11va conferencia Argentina de Python
4, 5 y 6 de Diciembre de 2019
Acerca del evento
La PyCon (Python Conference) es una convención anual para la discusión y promoción del lenguaje de programación Python. Se originó en Estados Unidos pero hoy en día se realiza en ese país, en Europa, España, Brasil, Inglaterra, Italia, China, y en otros treinta países.
Desde 2009 se realiza también en Argentina, ese año en CABA, siendo declarado de Interés Cultural por la Ciudad de Buenos Aires. En consecuencia al carácter federal de nuestro país, las siguientes ediciones se realizaron en diferentes ciudades: Córdoba, Junín, Rosario, Quilmes, Rafaela, Mendoza y Bahía Blanca.
La PyCon Argentina reúne a gran parte de la comunidad de habla hispana, de todas las edades y con un fuerte acento en diversidad. Es gratuita y abierta a todo público, dirigida a profesionales, estudiantes, académiques, empresaries, trabajadores, funcionaries públiques, entusiastes; es decir, se trata de un evento inclusivo y para todes. El número de asistentes crece año a año, rondando las 1080 personas en el último año, en CABA.
En general el evento es de tres días: miércoles, jueves y viernes; el primer día de talleres y tutoriales y los siguientes dos días para charlas ya en formato conferencia clásica así como también espacios abiertos, talleres, y diferentes ámbitos pensados para la interacción de la comunidad de Python con otras comunidades, empresas e instituciones gubernamentales.
El material presentado incluye todos los niveles, desde lo más orientado a principantes como los talleres y tutoriales del primer día, hasta charlas de nivel avanzado con calidad internacional, dadas por invitades de otros países o por disertantes locales que también dan charlas similares en conferencias de otros países.
El evento está organizado por la comunidad de Python Argentina, cuyo objetivo es nuclear a les usuaries de Python y promover su uso. Python es un lenguaje de programación, de licencia abierta y libre, que es cada día más popular en la enseñanza, la industria y la ciencia, y es el lenguaje de mayor crecimiento en los últimos años. La comunidad cuenta con el soporte formal de la Asociación Civil Python Argentina.
Speakers


Actividades

Airflow para Data Scientists
Data Scientists: amantes de los notebooks, en eterna enemistad con los entornos productivos. Pero hay un patrón común a muchos proyectos de DS: el de un ET(F)L. Obtener los datos, preprocesarlos, modelar y disponibilizar el modelado es el núcleo que los define. Veamos como podemos agilizar y simplificar este flujo.
Con la intención de predecir la disponibilidad de bicicletas públicas en cada parada, pensaremos un flujo de trabajo para llevarlo a cabo. Veremos que el núcleo del proyecto son conceptos comunes a muchos proyectos de DS: obtener, preprocesar, modelar y disponibilizar. Entra Apache Airflow en escena para definir flujos de tareas programáticamente en Python, revisando los operadores más básicos que permiten que nuestro proyecto camine por sí solo.
Disertantes: Ignacio Javier Mermet

Análisis Exploratorio de Datos com Python
Una charla que muestra cómo usar Python para procesar datos y extraer información para la toma de decisiones.
El objetivo de la charla es demostrar técnicas y mejores prácticas para desarrollar rutinas ETL (Explore, Transform, Load) con Python y sus diversas bibliotecas de análisis de datos (Pandas, Matplotlib, Seaborn, etc.), mostrando a los oyentes cuán poderoso puede ser Python para obtener información y tomar decisiones basadas en datos.
Disertantes: João André

Aprendiendo CURSES y BLESSINGS para Terminal Scripting
En la charla voy a enseñarles las dos librerías blessings y curses, ambas usadas para el mismo fin: terminal scripting. Mostraré sus respectivas desventajas y ventajas y daré una breve introducción sobre cómo usarlas.
Primero comenzaré con una breve introducción hablando sobre los softwares de terminal, qué las hacen tan buenas y el por qué deberíamos usarlas. Una vez terminada la introducción de la charla, voy a enseñarles unas dos librerías muy interesantes llamadas "blessings" y "curses". Voy a hablar de ellas, contando sus respectivas ventajas y desventajas, cómo usarlas, etcétera. Será lo más parecido a una "clase" en vivo.
Disertantes: Martín Nieva

Astrofotografía pythónica con scikit-image y rawpy
Python tiene abundantes herramientas para astronomía y astrofotografía. Al que le interesa el tema, no tiene más que bajárselas y disfrutar. A menos que tu definición de disfrutar sea entender cómo funcionan y re-escribirlas "for the lulz". Si ese es el caso, esta charla es para vos.
Haremos un paseo por las herramientas necesarias para poder sacar fotos astronómicas, y los problemas que hay que resolver en el camino. Desde cómo abrir y decodificar imágenes RAW, hasta cómo funciona el proceso de stacking, la calibración de las imágenes, y el postprocesamiento necesario para conseguir una imagen decente del cielo. Veremos cómo funcionan algunas herramientas de automatización, porque pasar 4-5 horas en el frío de la noche invernal haciendo todo a mano no es ideal para la salud. También veremos ejemplos de aberraciones y problemas comunes, cómo resolverlos de ser posible, o cómo identificarlos de no serlo. Veremos nociones no demasiado en profundo de filtrado de imágenes, análisis morfológico, registración de transformaciones, plate solving, y del funcionamiento de los sensores de imágenes - suficiente para que una persona interesada pueda continuar investigando.
Disertantes: Claudio Freire

Buenas prácticas para lograr que el trabajo en Jupyter notebooks sea reproducible
Una charla en la que intentaré mostrar buenas prácticas aplicadas en el día a día de mi trabajo para poder reproducir Jupyter notebooks dentro de un equipo de Data Scientists.
El análisis y experimentación en Jupyter Labs es cada vez más común en empresas que necesitan explorar datos. Sin embargo la gran mayoría de ese trabajo es ejecutado pocas veces, ya que termina siendo muy difícil o incluso imposible de reproducir en el tiempo. Para resolver este problema propondré un flujo de trabajo que combina: * Identificadores de Issues/Tickets (Jira, Trello, Github Projects, etc.) * Sistemas de control de versiones (git) * Acceso a datos (Queries, S3, gdrive, etc.) * Manejo de dependencias en python
Disertantes: Diego Piloni
Caer con estilo: El modelo Buzz Lightyear de desarrollo de software
Programar es una actividad peculiar en la que uno intenta hacer cosas que no sabe cómo se hacen. Si las logra, se siente bien. Si no las logra, uno aprende. Cuáles son las lecciones que he aprendido no logrando hacer cosas?
Como no tenía buenas ideas de charlas, pedí en Twitter que me dieran temas y prometí dedicar algunos días a hacer lo que me propusieran. Facundo Batista propuso "Armar Desde Cero Un Orm Async Contra Pg." ¿Qué se yo de como hacer eso? Absolutamente nada. ¿Hay algo que me haga particularmente la persona correcta para hacerlo? ¡Más vale que no! ¿Entonces, que pasó cuando lo intenté? ¿Hay alguna cosa que haya aprendido que antes no sabía? ¿Funcionó? ¿Hice un ORM? La respuesta a esas y muchas otras preguntas que nadie se estaría haciendo, en esta charla.
Disertantes: Roberto Alsina

Celular, un testigo posible y silencioso
Describiré las técnicas usadas para identificar al asesino de una mujer a partir del análisis y decodificación de los archivos extraídos de celulares secuestrados, recuperado como prueba luego de haber sido revendido varias veces. Se describe la elaboración de un software libre realizado en Python para la descodificación de los archivos almacenados por la app de OLX
En la charla se introducen conceptos de informática forense en dispositivos móviles, explicando las características de la toma de muestras, luego se da un repaso de conceptos referentes a la tecnología móvil celular que son necesarios para realizar la investigación forense. Por último, se muestra el uso de un software realizado a medida para investigar bases de datos de una app usando SQLite y realizando el informe con Jinja2:
Disertantes: María Andrea Vignau
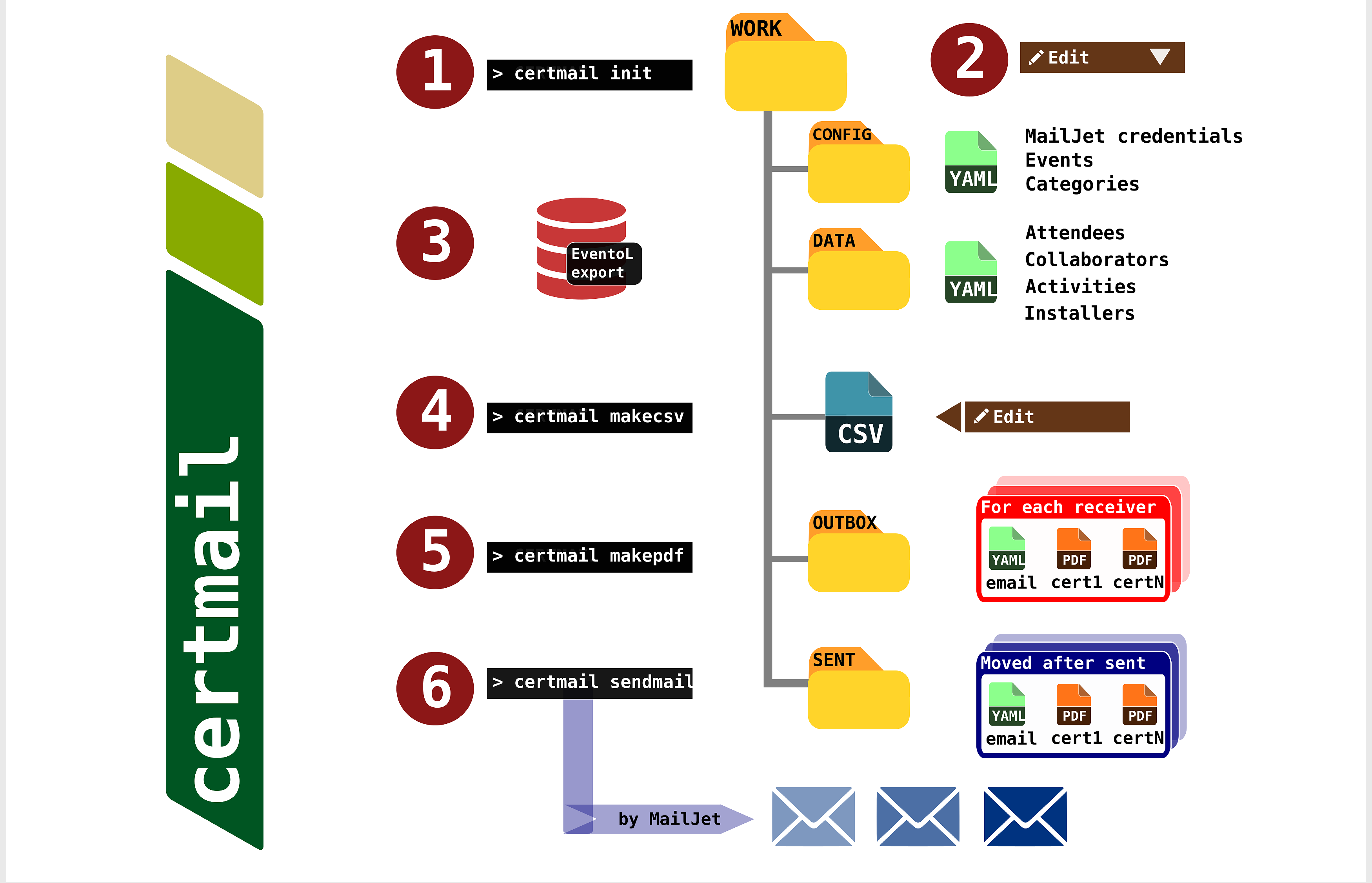
CertMailer - Automatizar envío de certificados
Terminan los eventos y muchos quieren un certificado de asistencia. Un detalle más para mantener el interés, para asegurar las inscripciones, una forma simpática y gratuita de recordar lo vivido. ¿Cómo lo hacemos? Automaticemos!
Explico la necesidad, los recursos encontrados, cómo combiné partes y cómo extraigo la información pertinente de EventoL ¿Qué más falta? Un montón: desafíos, issues, ideas
Disertantes: María Andrea Vignau
Cierre del III Concurso de Bioinformática para Escuelas Secundarias
Cierre del III Concurso de Bioinformática para Escuelas Secundarias
Este año la PyCon es sede del cierre del concurso de Bioinformática para escuelas secundarias. Un concurso en el que participan equipos de estudiantes de todas las escuelas que formaron parte del proyecto "La Bioinformática va a la Escuela" a lo largo del año. En este concurso las/los estudiantes tendrán que resolver algunos problemas biológicos utilizando sus los conocimientos de Python que adquirieron durante los talleres. El jurado del concurso está compuesto de investigadores del área de Bioinformática, quienes proponen las consignas y evalúan los trabajos. A fines de octubre se realiza un encuentro de cierre con entrega de diplomas para todos los participantes y premios que reconocen a los ganadores. Agradecemos al distinguido jurado: Dra. Elin Teppa, Dr. Diego Javier Zea, Dra. Marcia Anahí Hasenauer. Más información: http://ufq.unq.edu.ar/sbg/education/index.html Contacto: bioinfoalaescuela@gmail.com Twitter: @BioinformaticaA
Disertantes: Cierre Del Iii Concurso De Bioinformática Para Escuelas Secundarias

¿Cómo funcionan los Widgets de Jupyter?
Una de las características más importantes del ecosistema de Jupyter es la posibilidad que tiene el usuario de agregar interactividad a su desarrollo, dado que utiliza el navegador como elemento de interfaz de usuario. Esta interactividad se logra a partir de los Widgets que están conformados por un componente de backend en python y un componente frontend en javascript.
El objetivo de la charla es entender la estructura de los widgets y cómo funcionan dentro de los notebooks para poder implementar widgets propios. Vamos a ver en superficialmente como es la arquitectura de los widgets y cómo se maneja el comportamiento de los mismos. También veremos cuales son los protocolos que exponen los widgets, cómo utilizarlos y un par de consideraciones a tener en cuenta. Haremos un recorrido rápido por los widgets predefinidos y para finalizar recorreremos el desarrollo de un widget desde cero.
Disertantes: Augusto ( Sasha ) Kielbowicz

Conectando microservicios con Python
En esta charla presentamos las distintas pruebas y los resultados de comunicar cientos de microservicios en un contexto de alta demanda y performance. Cómo logramos bajar la latencia de todos los microservicios Python en una plataforma de alto tráfico.
Repasamos las librerías HTTP disponibles para hacer requests, cuáles son los casos de usos más comunes, porque elegir una sobre otra y compartir configuraciones avanzadas. Entender la importancia de mantener conexiones abiertas, pooling, reducir pedidos innecesarios al servidor de nombres (DNS). Analizar en profundidad cuáles son los side-effects de usar las librerías HTTP disponibles dentro de un servidor de aplicaciones. Al final de la charla presentamos algunos datos concretos de las mejoras obtenidas con muy poco esfuerzo de desarrollo pero con mucha lectura de documentación
Disertantes: Rodolfo E. Edelmann

Configuration-friendly apps.
La configuración es solo otra API de una aplicación, dirigida a usuarios que la instalarán y ejecutarán. Es un aspecto importante de la arquitectura de cualquier sistema. Pero a veces se la pasa por alto. El propósito de esta charla es explorar una solución propuesta para la administración de configuración de una app en general, y para una app Python en particular.
En esta charla, analizaremos los diferentes tipos de configuraciones, la diferencia entre configurar una biblioteca y una aplicación, los enfoques para administrar la configuración y los secretos de su aplicación para diferentes entornos, y ofreceremos una descripción general de las herramientas disponibles para la producción. También expondremos por qué no es una buena idea hacer que su aplicación sea configurable a través de archivos ejecutables (como settings.py o .vimrc), cuándo usar argumentos de CLI, vars ENV, archivos ini, etc. e introducir prettyconf, una biblioteca que condensa todas estas prácticas para permitir a los desarrolladores usar diferentes estrategias para configurar sus aplicaciones.
Disertantes: Hernan Lozano

Conociendo las baterías de Python
La idea de la charla es mostrar "las baterías de Python", es decir, conocer los módulos de la librería standard (y no tan standard) qué tenemos a nuestra disposición y que mucha aveces terminamos reinventando porque no conocemos algún módulo.
Comenzaremos contando porque se considera que Python tiene baterías incluídas. Recorreremos módulos de la libreria standard comentando sus usos y ejemplos. Luego veremos módulos que no usamos comúnmente pero tienen mucho que aportar por ej. Itertools, functools, concurrent, etc. Por último conoceremos librerías que no están en la librería standard pero que cualquier pythonista se alegra de conocer.
Disertantes: Martín Alderete

¡Construyamos juntos! Cómo y por qué tener un PyPi interno en tu organización.
Con un PyPi interno es fácil construir herramientas de forma colaborativa. En este espacio vamos a charlar sobre sus beneficios, y cómo levantarlo fácilmente con PyPiCloud.
Tener un repositorio interno de paquetes Python en tu organización le va a ahorrar a todos muchísimo tiempo y dolores de cabeza. Facilita la colaboración entre equipos, permite generalizar soluciones complejas del negocio, colabora con propagar buenas prácticas de modularización, ayuda a abstraer el código de las decisiones de infraestructura, facilita la auditoría, etc. Esas son solo algunas de las ventajas de tener un PyPi interno en tu organización. Y lo mejor de todo: ¡lo podés tener andando rapidísimo!
Disertantes: Sofía Denner

¡Contribuir al Software Libre es la tarea!
Como desarrolladores de software, no debemos de quedarnos únicamente en el uso de las herramientas libres, sino también, poder aportar desde nuestro conocimiento a los proyectos con los que trabajamos diariamente. Una charla de concientización tomando como ejemplo un proyecto de Software Libre y Comunitario como Tryton.
Como desarrolladores de software, no debemos de quedarnos únicamente en el uso de las herramientas libres, sino también, poder aportar desde nuestro conocimiento a los proyectos con los que trabajamos diariamente. Una charla de concientización tomando como ejemplo un proyecto de Software Libre y Comunitario como Tryton.
Disertantes: Luciano Rossi
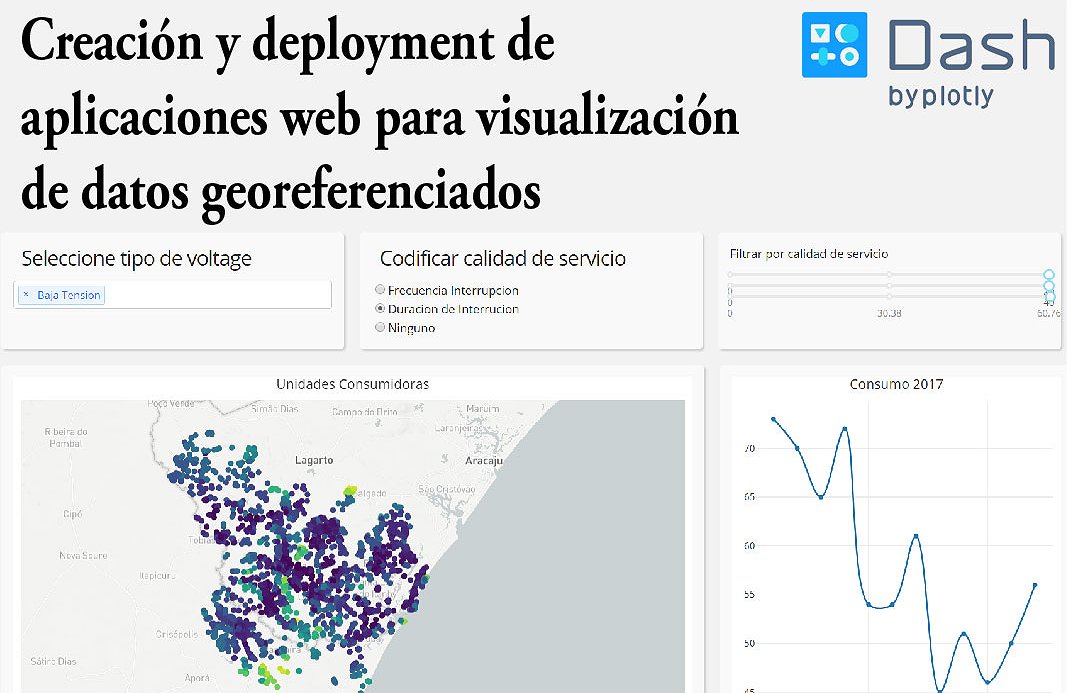
Creación y deployment de aplicaciones web para visualización de datos georeferenciados
El objetivo del tutorial es la creación de una aplicación web usando Dash, en donde podamos mostrar información georeferenciada (mapa interactivo), en este caso particular trabajaremos con un dataset de consumo electrico en Brasil donde podremos localizar los diferentes consumidores, filtrarlos, codificarlos en base a diferentes variables y mostrar información adicional.
Creación y deployment de aplicaciones web para visualización de datos georeferenciados Existen varias librerías para visualización de datos, sin embargo existen muy pocas que proporcionen las herramientas para poder compartir estas visualizaciones de manera abierta, fácil y sin tener que utilizar otros lenguajes. En este presentación se muestra como podemos realizar una visualización interactiva y publicarla fácilmente como una webapp en un par de líneas y 100% en python. Crearemos una aplicación para visualizar los consumos de energia de distintas distribuidoras brasileras utilizando Dash una extension de Plotly para crear webapps. Esta constara de un mapa interactivo con diferentes tipo de consumidores de los que podremos visualizar sus hábitos de consumo, características de conexión, e informacion contextual. También al estar basado en Flask veremos como podemos extender las capacidades de la librería integrandola a una aplicación de este tipo.
Disertantes: Ramiro Caro

Creating Microservices with Django Rest Framework
The whole idea is present to the audience how it's easy to create a microservice with Django Rest Framework
This is gonna be a hands-on presentation where my purpose is to use some slides to present the DRF framework and then walk through the code showing how it's simple to create a microservice using Django, Django Rest Framework. The agenda is gonna be: - Introduction (give some numbers to the audience about Django); - Talk about DRF (Serializers, Views, configurations etc) - Hands-on session (Creating a simple endpoint using Django and DRF)
Disertantes: Alexandre Rosa

Cultura Constructiva y visión tecnológica
¿Qué aspectos hay que mirar para evaluar la “salud tecnológica” de mi proyecto? ¿Qué cosas son más importantes que otras? ¿Qué dinámicas de equipo tienen sentido? ¿Cómo hacemos para unificar los criterios tecnológicos entre los distintos equipos de la empresa? ¿Cómo evitamos reinventar la rueda en cada proyecto?
¿Qué aspectos hay que mirar para evaluar la “salud tecnológica” de mi proyecto? ¿Qué cosas son más importantes que otras? ¿Qué dinámicas de equipo tienen sentido? ¿Cómo hacemos para unificar los criterios tecnológicos entre los distintos equipos de la empresa? ¿Cómo evitamos reinventar la rueda en cada proyecto? En esta charla te queremos contar cómo respondimos estas cuestiones (y muchas otras más), apalancados en los aspectos culturales de la organización, consolidando una visión y obvio, escribiendo una herramienta en Python. Sin ser específicos, vamos a hablar de coding style, testing, branching model, scrum, infra, code reviews, documentación...
Disertantes: Carlos Matías De La Torre (A.K.A. Litox) Y Javier Mansilla

Data-science a escala, con Python, en Mercadolibre
El foco de la charla está en las diferencias entre el desarrollo de un prototipo o POC de machine-learning y un servicio productivo, a escala. Para eso, voy a contar sobre el desarrollo que hicimos, en Mercadolibre, de una plataforma para agilizar el desarrollo y despliegue de modelos entrenados.
Para tratar el tema de la distancia entre el desarrollo experimental de un modelo de machine-learning y los desafíos de servirlo como un servicio production-ready, voy a aprovechar una experiencia de la vida real. En Mercadolibre existe Fury: una plataforma de infraestructura y desarrollo, para el despliegue de microservicios. La misma provee features para build, deploy, gestión de entornos de desarrollo, automatización de la creación de infraestructura, monitoreo, métricas, servicios, etc. Es uno de los principales factores que permitió crecer de 400 desarrolladores a los ~3000 que somos ahora, en pocos años. El problema es que dicha infraestructura no fue diseñada para lidiar con las particularidades asociadas a los sistemas de machine-learning: entornos de experimentación para data-scientists, procesos de ETL, entrenamiento de modelos, acceso a infraestructura específica como GPU, etc. Entonces, en un esfuerzo transversal a la organización, con la colaboración de varios equipos, desarrollamos Fury Data Apps: una extensión a Fury que provee herramientas y servicios para que cualquiera pueda diseñar, experimentar, desarrollar y desplegar sistemas basados en machine-learning, a la escala que Mercadolibre necesita. En esta charla voy a presentar: * las características principales de la plataforma * los problemas que soluciona * el stack tecnológico que la soporta * en general, cómo cubre el gap entre un POC y un sistema production-ready
Disertantes: Carlos Matías De La Torre (A.K.A. Litox)

Desmitificando python: típicas preguntas del primer tiempo
Los parámetros se pasan por valor o referencia? Las variables tienen tipo? Es python compilado, interpretado, u otra cosa? Vamos a responder estas y varias otras preguntas típicas que suelen surgir luego de dar nuestros primeros pasos con el lenguaje.
Dando clases noto mucho la necesidad de dar algunos pasos extras después de leer los típicos tutoriales, cuando los alumnos empiezan a programar cosas más reales. Hay preguntas y malos entendidos que se repiten a lo largo de los años, y por este motivo creo que un "post-tutorial" donde podamos responder esas preguntas, puede ser muy útil para la gente que está aún empezando a adentrarse en python. Temas que seguramente se abarcarán: manejo de referencias (variables), tipos mutables vs inmutables, tipado estático vs dinámico y fuerte vs débil, y modelo de ejecución de python (compilado a lenguaje intermedio).
Disertantes: Juan Pedro Fisanotti

El bug invisible
La arquitectura de nuestro sistema va a definir su futuro ¡Por sistemas con una vida prospera!
En la charla vamos a hablar de los sintomas de malas arquitecturas y proponer ideas para solucionar los problemas comunes a los diseños de sistemas. Referencias: Clean Architecture - Robert Martin
Disertantes: Yonatan Romero

El desafío de ENSEÑAR PYTHON a nivel universitario
Enseñanza de programación Python a alumnos informáticos y no informáticos.
La enseñanza de programación siempre ha sido un desafío tanto para los profesores como para los alumnos. Desde hace varios años venimos enseñando Python a nivel universitario a los alumnos de carreras de ingeniería, ya sean informáticos como no informáticos.
Disertantes: Lic. Felipe Morales

El onboarding es invisible a los ojos
Ingresar una nueva persona al equipo es y debe tomarse como un momento importante tanto para quien ingresa como para el equipo. Algunas experiencias (propias y ajenas) y algunas conclusiones al respecto.
Ingresar una nueva persona al equipo es y debe tomarse como un momento importante tanto para quien ingresa como para el equipo. Algunas experiencias (propias y ajenas) y algunas conclusiones al respecto.
Disertantes: Mati Barriento

Enseñar programación y robótica sin morir en el intento
¿Cómo no enseñar programación y Robótica? ¿Por qué promover la enseñanza en los más chicos? Mitos y realidades. La mirada del mundo nerd.
Son temas que "están de moda". Sin embargo, existen muchas dificultades al momento de trabajar estas temáticas, especialmente con los más chicos. Durante la charla se abordarán los errores más comunes al momento de transmitir estos conocimientos y las habilidades que se pueden desarrollar incorporando actividades STEM.
Disertantes: Romina Fairbairn

Entendiendo asyncio sin usar asyncio
Tratando de entender asyncio con cero conocimientos previos de asincronismo.
Asyncio nos permite programar concurrencia colaborativa en Python, algo muy útil en muchas situaciones. Pero puede resultar un poco difícil de comprender durante el primer tiempo, ya que requiere (como todo framework de async), algunos cambios de mentalidad y comprensión de un par de conceptos "extraños". En esta charla intentaremos entenderlo desde un enfoque constructivo, asumiendo cero conocimientos previos de asincronismo.
Disertantes: Juan Pedro Fisanotti

En un mundo de unos y ceros, vamos por la diversidad
Inclusión, visibilidad y espacios seguros para mujeres e identidades diversas dentro del mundo IT.
Inclusión, visibilidad y espacios seguros para mujeres e identidades diversas dentro del mundo IT.
Disertantes: Las De Sistemas

Fuzz & Property Based Testing
Introducción al origen de fuzz testing a través de los papers de Miller. Luego, la diferencia entre fuzz y property based testing y como aplicamos esto a nuestros programas de python de todos los días, usando hypothesis.
A medida que el avance de la tecnologías mueve la frontera de lo posible en el desarrollo de software, nuestras aplicaciones cada vez tienen más features y se vuelven mucho más complejas. Dicha complejidad trae consigo una inherente fragilidad. En esta charla haremos un repaso del trabajo científico de Barton Miller, su aporte al Fuzz Testing (tests con input aleatorio) y una variación moderna llamada Property Based Testing. Presentaremos evidencia que nos permite afirmar que un 30-40% del software tiene bugs que podrían ser detectados con estas técnicas. Luego, vamos a hacer una demo sobre cómo aplicar estas técnicas a programas existentes, aparentemente correctos y entender cómo pueden ocultar errores aunque tengan tests convencionales (unit test) y cobertura del 100%
Disertantes: Pablo Fernandez

Grafos temporales sobre NetworkX
El presente trabajo busca mostrar una capa de software construida utilizando el paquete networkX que nos permite trabajar con la variable tiempo cuando estudiamos estructuras de grafos.
El módulo de grafos temporales que se presentará en la exposición sigue las especificaciones propuestas por el profesor Vassilis Kostakos en su trabajo "Temporal Graphs" de 2009. El objetivo es introducir el estudio de grafos que contemplan la variable del tiempo, sus definiciones y sus métricas para que al finalizar la charla contemos con una herramienta de análisis más para trabajos afines.
Disertantes: Leonardo Morales

High Perfomance Pandas: Leveraging the power of pandas data manipulation.
Pandas is an standard data handling library commonly misused, however, this powerful library includes a set of APIs created for high speed data manipulation hidden to most of people. This talk will show how to use pandas properly, performance benchmarks against basic data structures and provide a deeper understanding of pandas data handling. This talk aims to help making data analysis work easier and cleaner by exploiting the full power of pandas.
This talk gives a walkthrough pandas API, showing all the requeried tools for day-to-day work of every data analyst or data scientist, * Intro * Starting a pandas data set from scratch *Combining DataFrames: * Merge * Concat * Append * Functional Approach: * Using Lambda functions * Using defined functions * Data Querying: * The .at & .iat operator * Loc, query, eval * Multi-level index * Series and DataFrames Operations * Selecting Columns * Windowing & Expanding * Grouping and Aggregations: * .groupby * Merge, join, concat, & append * Aggregations
Disertantes: Luis David Camacho

Ignis, una herramienta computacional para la educación, la ciencia y la innovación
Charla de presentación de Ignis, un software de cálculo simbólico desarrolaldo en Python y C++ que tiene aplicaciones a la educación e investigación. En esta charla se discutirá el estado de avance del proyecto, se realizarán pruebas en vivo del poder de computo de este CAS y se discutiran mejoras antes del lanzamiento oficial.
El creciente uso de las tecnologías de innovación hace necesario el desarrollo de nuevas competencias dentro de la educación formal, siendo la enseñanza y el aprendizaje de la programación de importancia estratégica en la formación profesional. En este contexto nace el proyecto Ignis, como una herramienta para ayudar al desarrollo de la lógica computacional y el aprendizaje de Python mediante la resolución de problemas matemáticos y físicos, además de proveer un entorno dinámico para la computación interactiva simbólica y numérica a nivel profesional ya que fue diseñado y desarrollado para usuarios inexpertos y avanzados en programación. Desde el punto de vista técnico, Ignis provee un entorno multiplataforma desarrollado en C++, y un Kernel que utiliza una sintaxis simplificada basada en el ecosistema Python, permitiendo a los usuarios realizar operaciones complejas despreocupándose a cierto grado de las sutilezas del lenguaje. El objetivo central del proyecto es acercar a las nuevas generaciones a entornos digitales de aprendizaje, achicando las barreras y mostrando que la programación se encuentra al alcance de todos, además facilitar el aprendizaje e implementación de un lenguaje multipropósito de transcendencia mundial a temprana edad colaborando con el desarrollo del pensamiento lógico mediante la resolución de problemas.
Disertantes: Gonzalo Quiroga

Introducción a Python y Pandas para usuarios de Excel
La idea es mostrarle a los usuarios de Excel, como utilizar Python y Pandas como complemento para sus tareas de análisis. El énfasis está puesto en la manipulación de datos con Pandas, especialmente con data frames y de Pivot Table.
Actualmente muchas empresas están intentando crear una cultura de datos a nivel organizacional. En esos proyectos un tema que surge siempre es como darles más herramientas a los usuarios de Excel, para mejorar su productividad y convertirlos en analistas de datos. Uno de los primeros pasos que suelo proponer, es capacitarlos y ayudarlos a incorporar Pandas para realizar tareas de manipulación de datos con mayor facilidad, superando las limitaciones que tiene Excel. Los puntos que propongo tratar en la charla son los siguientes: 1. Porque conviene incorporar Python y Pandas. 2. Equivalencia de elementos entre Excel y Pandas. 3. Importación de archivos de texto y Excel. 4. Creación de data frames y manipulación básica. 5. Transformación y combinación de múltiples data frames. 6. Reemplazo de las tablas dinámicas de Excel con Pandas Pivot Table. Apunto a una audiencia con conocimientos mínimos de Python. En las capacitaciones en empresas doy una breve introducción a Python desde cero, pero no hay espacio para en una charla de 45 minutos.
Disertantes: Fernando González Prada

Introduccion a TDD: Uso luego implemento
Entendiendo TDD y como nos simplifica el desarrollo de cualquier proyecto pensando en el uso y no en la implementación.
Comenzaremos el desarrollo en Python de un proyecto utilizando TDD y programación orientada a objetos. Previamente hablaremos sobre los conceptos fundamentales de TDD. Usaremos framework para realizar pruebas en nuestro código y así asegurarnos de romper lo menos posible al realizar alguna modificación. Por ultimo veremos una posible implementación en un esquema de Integración Continua con Github y TravisCI.
Disertantes: Matias Pereira

Keynote - Martin Sarsale
Keynote - Martin Sarsale
Keynote - Martin Sarsale
Disertantes: Martin Sarsale

Levantar una aplicación Django productiva de cero
En devartis elaboramos un repositorio template con todos los pasos necesarios para el setup de una aplicación de Django (chequeos de code style, unit tests, deploy automático...) El proyecto ahora es de código abierto y lo revisaremos en esta charla.
En devartis trabajamos con Django por muchos años y siempre estábamos repitiendo lo mismo al comienzo de cada proyecto. Chequeos de pycodestyle, unit tests, deploys automáticos... Repetíamos el setup una y otra vez y, ocasionalmente, nos perdíamos cosas importantes que nos habrían facilitado la vida. Es por eso que decidimos crear y mantener un repositorio template con todas las herramientas necesarias para iniciar un proyecto Django. Resultó muy valioso para la empresa y es por eso que queremos compartirlo con la comunidad. El proyecto ahora es de código abierto y lo revisaremos en esta charla.
Disertantes: Dylan Gustavo Alvarez Avalos

LinuxChix: Open source minds
LinuxChix Argentina comenzó a mediados del 2014 de la mano de un grupo de usuarios de Linux con diferentes antecedentes pero con un objetivo en común: establecer un grupo de usuarios técnicos y crear un ambiente positivo para ayudar a que más mujeres de Argentina se involucren tanto con Linux como con el software libre en general.
LinuxChix Argentina comenzó a mediados del 2014 de la mano de un grupo de usuarios de Linux con diferentes antecedentes pero con un objetivo en común: establecer un grupo de usuarios técnicos y crear un ambiente positivo para ayudar a que más mujeres de Argentina se involucren tanto con Linux como con el software libre en general.
Disertantes: Gessica Paniagua

Live Typing - Anotación automática de tipos para lenguajes dinámicos
Los lenguajes dinámicamente tipados adolecen de información de tipos lo cual dificulta la implementación y precisión de herramientas de refactoring, búsqueda y autocompletion entre otras. Varias propuestas han aparecido para agregar información de tipos a estos lenguajes, desde gradual typing hasta explicit type annotation, que se centran en ofrecer un chequeo de tipos 'a la static typing' en vez de potenciar la característica dinámica de este tipo de lenguajes. Live Typing es una solución distinta y novedosa que provee información de tipos automáticamente, sin intervención del programador y sin modificar la sintaxis del lenguaje. El grupo de investigación de 10Pines lo ha implementado en varios lenguajes dinámicos y presentaremos en esta charla de qué trata, cómo está implementado y qué beneficios trae a lenguajes dinámicos como Python.
Los lenguajes dinámicamente no poseen información de tipos explicita en sus variables, parámetros ni retorno de mensajes. Esta falta de información dificulta la implementación y precisión de herramientas de manipulación de código como rename de mensajes, autocomplete, búsqueda de senders e implementors entre otras. Live Typing es una técnica que a partir de una modificación sencilla de la VM de los lenguajes de objetos, recolecta información de tipo de manera automática cada vez que un objeto se asigna a una variable o parámetro y cada vez que se retorna de un método. Esta información es accesible desde el ambiente de desarrollo y con la misma se puede mejorar drásticamente las herramientas de tal forma que se comporten de manera similar a la de lenguajes estáticamente tipados. Como ventajas adicionales, se puede implementar un chequeo de tipos "constructivo" y no "punitivo", potenciando las ventajas de los lenguajes dinámicamente tipados. Una de las características más interesante de esta técnica es que no es necesario modificar la sintaxis del lenguaje y los programadores no se ven impactados para nada en su manera de desarrollar, o sea, Live Typing pude o no ser utilizado y si lo es, su adopción es no intrusiva. Al día de hoy, Live Typing está implementado en Smalltalk y Ruby y ya lo hemos presentado en distintos congresos internacionales. El objetivo es tener un prototipo/primer versión en Python funcionando para la presentación del congreso.
Disertantes: Hernan Wilkinson
Lo que nadie te dijo de migrar a Python 3
Resumen: Trabajamos sobre un proyecto de 6 años, y tuvimos que migrarlo a Python 3. Que puede malir sal? Veni a ver las cosas buenas (y malas) que nos encontramos en el proceso.
Cuando en 2013 se arrancó a desarrollar el producto en el que trabajamos, Python 3 ya tenía 5 años de antigüedad. Sin embargo, el poco soporte que tenían algunas librerías y distros de GNU/Linux hizo que se terminara eligiendo hacerlo en Python 2. Seis años después y 60,000 líneas de código más adelante, las cosas cambiaron considerablemente: se anunció que en 2020 se va a retirar el soporte para Python 2.7, y tras esta noticia las distros y librerías empezaron a pasarse a Python 3. Las mismas razones que en un momento nos impidieron usar py3 hoy son las que nos fuerzan a que migremos. Sin embargo, todo se hace más difícil teniendo que migrar tanto código en tan poco tiempo. Vamos a hablar de los problemas y beneficios que trajeron las tools automáticas, las frustraciones que nos trajo convertir nuestro proyecto en paquete de PyPI, la importancia de tener unit tests en el código, y de detalles para hacer código compatible con Python 2 y 3 a la vez. Esperamos que quienes vean nuestra charla se sientan motivados a migrar a Python 3 y que sepan solucionar los problemas con los que nos encontramos.
Disertantes: Matias Lang, Eric Horvat

Los desafíos de formar a la nueva generación de chicas líderes en tecnología
Datos sobre la brecha de género en Argentina y qué estamos haciendo desde Chcias en Tecnologia junto a las comunidades y el ecosistema tenologico-emprendedor para achicarla.
Datos sobre la brecha de género en Argentina y qué estamos haciendo desde Chcias en Tecnologia junto a las comunidades y el ecosistema tenologico-emprendedor para achicarla.
Disertantes: Chicas En Tecnología

Machine Learning y grafos
La charla tiene como objetivo hacer una introducción sobre el tema del aprendizaje automático y mostrar cómo aplicarlo a datasets que sean redes. Usando ejemplos open source y datos de citas y redes sociales (Twitter), mostraremos cómo estas técnicas y algoritmos permiten obtener mejores performance en tareas diarias de aprendizaje automático.
En los últimos años, la cantidad de datos disponibles ha aumentado drásticamente. Sin embargo, etiquetar dichos datos es muy costoso. En este escenario, el aprendizaje semi-supervisado emerge como una herramienta de vital importancia, que combina datos etiquetados (aprendizaje automático supervisado) y datos no etiquetados (aprendizaje no supervisado) para hacer mejores predicciones. En particular, los algoritmos basados en grafos tienen en cuenta las relaciones entre las instancias de los datos y las estructuras de gráficos subyacentes para hacer esas predicciones.Además, en el contexto del análisis de datos, hay escenarios que pueden considerarse naturalmente como grafos. Esto ocurre en situaciones donde además de las propiedades individuales de cada instancia, la conectividad entre los elementos del conjunto de datos también es importante (como por ejemplo personas en una red social). Por lo tanto, es lógico que los modelos de aprendizaje automático incluyan información tanto de un nodo como de sus vecinos al hacer una predicción. En esta charla, haremos una breve introducción al aprendizaje automático, recapitularemos distintos modelos y algoritmos para atacar el problema (redes convolucionales en grafos y términos de regularización dependientes de la red) y mostraremos ejemplos y aplicaciones con la intención de que los participantes puedan comenzar a entender y aplicar dichas herramientas y técnicas en sus problemas de aprendizaje automático. Los ejemplos que contaremos incluirán desde redes de citas de papers hasta redes de discusión política en twitter.
Disertantes: Federico Albanese, Leandro Lombardi
Message in a BOT-tle
Aumentar la productividad laboral, generar ingresos por publicidad o simplemente para pasar el rato. Programar bots puede ser un desafío interesante, en el fondo, hacer que varias APIs hablen entre ellas abre las puertas a un mundo creativo del cual podemos sacar mucho provecho.
Charla dedicada a explicar un universo nuevo de posibilidades que abren los bots en su interacción con distitnas APIs Explicación de los casos de uso más comunes, orientados a: Mejora de productividad - Integración Slack / Github Atención al cliente - Bots en Facebook Messenger / Telegram Diversión - Bots en Twitter (con posibilidad de monetización)
Disertantes: Mauricio Ghiorzi

Modernizando la clase de Simulación con Python (¿Cómo aprendí Python para dar clases de Simulación?)
Se contará la experiencia de actualización de la materia Simulación (Carrera Terciario Analisita de Sistemas). Se pasó de simular en Excel a Python.
Realizaremos un pequeño repaso de simulación de variables aleatorias a modo introductorio del tema. Veremos el proceso actualización de una materia que llevaba una década sin actualizarse (¡se utilizaba simulación en Excel en una carrera de Sistemas!). Analizaremos los desafíos del docente y alumnos ante un lenguaje nuevo de programación. Si, hablamos de Python. Presentaremos la librería Ciw para simulación de Colas de Espera (eventos discretos).
Disertantes: Pablo Akerman

no podemos innovar si seguimos realizando tareas manuales
Ansible es la herramienta que permite fácilmente automatizar todas las tareas de administración, configuración, provisión y orquestación de software en todo tipo de dispositivos, solo basta que en el equipo remoto (router, switch, smartphone, server, virtual server, etc) tenga python y ssh :) El desarrollo de *playbooks* y roles es sencillo, fácil de comprender y existe una gran comunidad que libera soluciones completas.
Ansible es la herramienta que permite fácilmente automatizar todas las tareas de administración, configuración, provisión y orquestación de software en todo tipo de dispositivos, solo basta que en el equipo remoto (router, switch, smartphone, server, virtual server, etc) tenga python y ssh :) El desarrollo de *playbooks* y roles es sencillo, fácil de comprender y existe una gran comunidad que libera soluciones completas.
Disertantes: Osiris Gómez, Cristian G. Segarra

Objetos en Python de 0 a 99,9
En la charla hablaremos sobre la programación orientada a objetos, como usarla en Python y como los patrones de diseño nos pueden ahorrar varias horas de trabajo.
El inicio de la charla esta orientada a alguien que no sabe programar en objetos, pero para quienes ya lo saben no esta mal repasar un rato. Hablaremos de algunas ideas relacionadas a OOP (Object Oriented Programing) como clases, objetos, polimorfismos y delegación de responsabilidades entre otras. También veremos algunas buenas practicas para tener código mantenible por otros o por nosotros dentro de algunos meses. Después de tener una base charlaremos acercar de los patrones de diseño, que son y como nos pueden ayudar en el día a día.
Disertantes: Matias Pereira
PEPificate: 10 PEPs a los que deberías prestarles atención
Leer documentos de estándares es una tarea dura. Pero como en otros campos, los estándares en Python juegan un papel muy importante. En esta charla vamos a repasar una lista resumida de los PEPs más importantes a la fecha, y ver como influencian la creación de código.
Leer documentos de estándares es una tarea dura. Pero como en otros campos, los estándares en Python juegan un papel muy importante. Los Python Enhancement Proposals (PEPs) son definidos, mejorados y eventualmente implementados por la comunidad. Aplican casi a todo lo relacionado con Python, de lo más abstracto y general a lo más concreto y específico. Prestarles atención y saber cuáles leer de antemano es una tarea vital que debería suceder antes de escribir las primeras líneas de código en un proyecto. En esta charla vamos a repasar una lista resumida de los PEPs más importantes a la fecha, y ver como influencian la creación de código. De guías de estilo y convenciones de docstrings a data classes y expresiones de asignación. Vamos a ver cómo estos PEPs afectan (o pueden afectar) el código que escribimos, y cómo podemos usarlos para mejorar nuestro código y hacer que el desarrollo sea más fácil y divertido. Luego de esta charla, los asistentes tendrán un mejor entendimiento sobre por qué los PEPs son importantes en Python, cuáles tienen que ser leídos, y cuáles se deberían usar como guía en el futuro, tanto para el desarrollo desde cero como para el refactoring.
Disertantes: Juan Manuel Santos
Pipeline Jungles: Es una selva ahí fuera
Alguna vez deployaste un modelo de ML a producción? Y 20 en simultáneo? En esta charla vamos a hablar de todos los anti-patterns y dolores de cabeza que surgen a la hora de orquestar el deploy y reentrenamiento de N modelos a producción, cuando N es mayor a 100. Vamos a aprender qué son los pipelines jungles, la deuda técnica de integración, y nuestra solución en ASAPP para resolverlo.
En esta charla vamos a hablar sobre toda la deuda tecnica que es generada por el machine learning de manera encubierta. Como el pipeline del reentrenamiento de modelos y datos usualmente conlleva mucho "glue code" entre diferentes librerias y como ese glue code resulta muy dificil de testear, modularizar, orquestar y suele traer muchos problemas de regresion. Luego vamos a avanzar a discutir sobre diferentes formas de orquestar la plataforma de rentrenamientos, diversos fallos que tuvimos en ASAPP, lecciones aprendidas y caminos a seguir.
Disertantes: Axel Sirota
Procesing big data with Vaex, dataframes and no clusters
Data is getting bigger and bigger, making it almost impossible to processed it in desktop machines without using a full clusters infrastructure, limiting experimentation. A way to archive this is using Vaex, Python library, with a similar syntax to Pandas, that help us to work with large data-sets in machines with limited resources were the only limitation is the size of your hard drive.
Nowadays data is getting bigger and bigger, making it almost impossible to processed it in desktop machines. To solve this problems, a lot of new technologies(Hadoop, Spark, Presto, Dask, etc.) have emerged during the last years to process all the data using multiple clusters of computers. The challenge is that you will need to build your solutions on top of this technologies, requiring designing data processing pipelines and in some cases combining multiple technologies. However, in some cases we don't have enough time or resources to learn to use and setup a full infrastructure to run a couple experiments. Maybe you are a researcher with very limited resources or an startup with a tight schedule to launch a product to market. A way to archive this is using Vaex, Python library, with a similar syntax to Pandas, the help us to work with large data-sets in machines with limited resources were the only limitation is the size of your hard drive. Vaex provides memory-mapping, so it will never touch or copy the data to memory unless is explicitly requested.
Disertantes: Marco Carranza
Python en Debian: desde la visión de un novato.
Empaquetado de proyectos Python para Debian. Un paseo rápido sobre cómo empezar a contribuir en Debian.
Durante esta charla se pretende dar a conocer mi experiencia manteniendo paquetes (Python) en Debian. Se va a presentar resumidamente, cómo es uno de los pasos para comenzar a contribuir a este Sistema Operativo. Se mostrará el uso de git-buildpackage, una herramienta sencilla para empaquetar desde git, a través de un ejemplo sencillo, y luego qué hacer con ello para que sea aceptado nuestro paquete en Debian. Por último, se dará a conocer que en Debian se quitará el soporte de Python 2 a partir de Bullseye. Todo desde el punto de vista de un Novato.
Disertantes: Arias Emmanuel
Python para Contadores y Administrativos
El objetivo es mostrar herramientas prácticas de cómo los Contadores y personal administrativo pueden optimizar su trabajo diario con Python. La charla tiene un espíritu de romper barreras e invitar a público no IT a sumarse a este maravilloso lenguaje.
Temas de la charla: - Introducción a la charla - Manejo de CSV con Python - Manipulación de archivos Excel - Manipulación de archivos PDF - Generación de gráficos - Automatizar tareas con el sitio web del AFIP - API de BCRA
Disertantes: Gustavo Mena

Qué es y qué hacemos WWCode - Nuestros primeros 6 meses de gestión
El objetivo de la charla es dar a conocer nuestra comunidad global, su mision y visión, en qué principios se basa y cómo a seis meses de gestión estamos siendo agentes de cambio para recortar la brecha de genero en sistema en el chapter de Buenos Aires.
El objetivo de la charla es dar a conocer nuestra comunidad global, su mision y visión, en qué principios se basa y cómo a seis meses de gestión estamos siendo agentes de cambio para recortar la brecha de genero en sistema en el chapter de Buenos Aires.
Disertantes: Silvia Daniela Belvedere

¿Qué tienen en común un código QR, un peluche, los Kanjis e ir a la casa de Damián?
El Pensamiento Computacional, a pesar de su nombre, es una habilidad humana que cada vez cobra más relevancia en la resolución de problemas en múltiples disciplinas. Pero, ¿qué es realmente, cómo podemos estimularlo y cómo se relaciona con la programación y el análisis de datos? Averigualo en esta charla.
En esta charla no vamos a explicar qué es el Pensamiento Computacional: ¡vamos a vivenciarlo! A través de cuatro actividades interactivas y desenchufadas vamos a descubrir junto con ustedes una forma diferente de pensar y resolver problemas. También, vamos a contar cómo las usamos para enseñar programación y análisis de datos con Python a jóvenes de cualquier carrera, chicos y chicas de primaria y docentes de todos los niveles en Argentina y Uruguay.
Disertantes: Franco Bulgarelli, Gustavo Trucco
Resolviendo la tarea con Jupyter
Es claro que la tecnología es algo que está inmerso en la vida cotidiana. Y además cada vez es más accesible el conocimiento de cómo sacarle provecho. Pero uno de los principales desafíos con los que une se encuentra es el no saber por dónde comenzar y luego superar el miedo a ser autodidacta. Por lo cual el taller se enfoca en ser un ejemplo de cómo experimentar con la computadora, aprovechando de las herramientas que ofrece Jupyter para realizar cálculos matemáticos, visualizaciones y agregar interactividad con controles de manera sencilla.
El objetivo del taller es introducir el uso de Jupyter como una herramienta para la enseñanza de contenidos curriculares en el colegio secundario. Principalmente enfocado en materias como Matemática y Física. Durante el taller se realizarán ejercicios y experimentos en los cuales cada une tiene que ir descubriendo las reglas para resolver el problema de manera iterativa e incremental. El enfoque consiste en que sea posible equivocarse constantemente y tener una respuesta inmediata para poder intentar nuevamente.
Disertantes: Augusto ( Sasha ) Kielbowicz
RTB en Jampp: Arquitectura, optimizaciones y otras yerbas
Cómo aprovechar la flexibilidad y el dinamismo de Python y transformarlo en una herramienta performante.
El modelo de negocios de Jampp se basa en real-time bidding, un ámbito que requiere bajas latencias y alta performance. Sin embargo, la mayoría de nuestros sistemas usan Python. Cómo hacemos para que un lenguaje de scripting pueda cumplir con requisitos tan estrictos ? Es aquí donde el ingenio, la experiencia y uno que otro hack nos mantiene a flote con un sistema que se banca miles de requests por segundo. La irrupción de golang y nuestras versiones custom de ZMQ, Tornado y otros.
Disertantes: Luciano Lo Giudice
Serpientes y Roedores
Se verán algunos aspectos y prácticas comunes de Go y cómo pueden ser aplicadas en Python para mejorar la calidad de nuestro código.
Se verán algunos aspectos y prácticas comunes de Go y cómo pueden ser aplicadas en Python para mejorar la calidad de nuestro código: - formateo consistente y estándard de código - diseño pensando en interfaces - buenas prácticas de logging
Disertantes: Ricardo Kirkner
Taller de Programacion para LGTBIQ y Mujeres
Taller de Programacion para LGTBIQ y Mujeres
Para participar se quiere inscripción, con cupos limitados. Próximamente más información.
Disertantes: Taller De Programacion Para Lgtbiq Y Mujeres

Trans-TI: Una empresa de IT que solamente emplea personas trans
En esta charla contamos sobre la experiencia de Trans-TI, una empresa que trabaja al revés, ve las habilidades que tienen las personas del colectivo y genera modelos de negocios válidos, apoyados por la tecnología o creándola.
En esta charla contamos sobre la experiencia de Trans-TI, una empresa que trabaja al revés, ve las habilidades que tienen las personas del colectivo y genera modelos de negocios válidos, apoyados por la tecnología o creándola.
Disertantes: Trans-Ti

uWSGI y Gunicorn - Cuando elegir uno o otro
Presente ejemplos de API web donde uWSGI y Gunicorn se puedan usar mejor.
- uWSGI - Modos: nginx + uwsgi con uwsgi protocol, nginx + uwsgi con http, http - centrarse en mode http (nginx es una otra charla) - como funciona - configuraciones más utilizadas Gunicorn: - Modo: Sync workers, Async workers (Gevent) - centrarse en Async (Gevent) - como funciona Gevent - monkey patch - libs - configuraciones más utilizadas - Benchmarks - uWSGI: pure python, database, remote request, remote request + database, multiple database and remote calls - Gunicorn + Gevent: - C libs: pure python, database, remote request, remote request + database, multiple database and remote calls - Pure Python libs: pure python, database, remote request, remote request + database, multiple database and remote calls
Disertantes: Tárliton Godoy

Viaje al centro de Django
¿Qué hace que Django sea tan poderoso? En esta charla examinaremos las funcionalidades de Python que le dan su poder y expresividad a Django.
Esta charla está dirigida a los usuarios asiduos de Django y principiantes en Python que quieran ampliar y profundizar sus conocimientos del lenguaje, independientemente de cualquier otro framework o biblioteca de terceros. En esta charla se verá cómo Django utiliza las features mas características de Python para llevar a cabo su poder y expresividad, a partir de ejemplos concretos extraídos del código fuente del mismo framework. El objetivo es un mayor entendimiento del funcionamiento interno de los aspectos más conocidos del framework y al mismo tiempo echar una mirada a las funcionalidades que diferencia a Python del resto de los lenguajes. Las funcionalidades que se examinarán son: - context managers: transacciones atómicas de db - decoradores: autenticación en views - generadores: evaluación de querysets - metaclases: definición de models - descriptores: Foreign key
Disertantes: Agustín Scaramuzza

Visor Ambiental. Herramienta para integrar datos científicos en intervención territorial sostenible.
Gran cantidad de datos científicos son de difícil acceso y se pasan por alto. Desarrollos en tecnologías web facilitan la creación de aplicaciones exploratorias. Creamos un Visor para consulta de datos de manera interactiva y dinámica para quienes necesiten datos confiables para intervención territorial en un contexto sostenible. El Visor Web esta desarrollado en Dash y Plotly.
Hoy en día la enorme cantidad de datos científicos y documentación específica a menudo resulta inaccesible. Estos grandes volúmenes de información producida por investigadores y consultores, abren oportunidades para que operadores, empresas y entes fiscalizadores compartan, integren y transfieran información valiosa a una base de datos común y dinámica, ayudando y fortaleciendo al desarrollo de intervenciones territoriales que consideren la conservación del ambiente. Los actuales desarrollos en tecnologías web (software) facilitan crear aplicaciones web exploratorias, vinculando datos científicos dentro de una herramienta interactiva logrando la accesibilidad de la información, garantizando la exploración y difusión de datos científicos apropiadamente. Los Visores de datos geográficos y ambientales pueden ser herramientas útiles para investigaciones, estudios de impacto ambiental y ordenamiento del territorio. El objetivo del Visor Web Ambiental es No depender de software complejo como las plataformas SIG. Pensamos en su diseño práctico, así cualquier persona maneja e investiga sus contenidos, sin conocimiento previo de geoinformática. El usuario accede intuitivamente e interactúa de manera simple, obteniendo información geográfica y ambiental fiable. Desarrollamos una plataforma de datos para condensar y sistematizar información geográfica y ambiental. Nuestro enfoque está destinado a fortalecer la consulta y transferencia de información de manera interactiva, dinámica y atractiva, destinada a investigadores y organismos que necesiten integrar datos confiables para desarrollar o fiscalizar intervenciones territoriales en un contexto de sostenibilidad ambiental promoviendo además la interacción de los sectores público y privado. Concomitantemente, establecimos procedimientos de actualización y verificación continua del Visor de datos proporcionando a los usuarios un mejor respaldo en sus intervenciones o toma de decisiones en la planificación e implementación de proyectos. El Visor Web esta desarrollado en Dash y Plotly.
Disertantes: Marcos Vaira, Ariel Silvio Norberto Ramos.

Workshop LEGO Education®: Creatividad, Innovación y Robótica Educativa
Desarrollo de habilidades y competencias en los estudiantes del siglo XXI mediante proyectos STEM (Science, Technology, Engineering & Mathematics). Experiencia de programación y robótica con Python.
En el workshop se propondrán diferentes actividades con modelos robóticos construidos con kits LEGO Mindstorms EV3. Los participantes utilizarán Python para programar los modelos: controlar sus motores, adquirir datos de los diferentes sensores y establecer respuestas a estos. No se requieren conocimientos previos sobre robótica. Se recomiendan conocimientos básicos de programación (no excluyente). Se requiere la utilización de computadoras que posean el editor Visual Studio Code con la extensión LEGO Education EV3 instalada y activada. Al menos una por equipo.
Disertantes: Equipo Pedagógico De Educación Tecnológica

μwsgi en producción: los defaults estan mal.
En varios de los equipos que participé, elegimos μwsgi como tecnología para servir nuestras aplicaciones python. Es una herramienta fantástica, con infinitas configuraciones, y lamentablemente las que trae por default no tienen sentido en producción. En esta charla se explora un pequeño conjunto de configuraciones que afectan en mayor o menor medida la calidad de una aplicación en producción.
En varios de los equipos que participé, elegimos μwsgi como tecnología para servir nuestras aplicaciones python. Es una herramienta fantástica, con infinitas configuraciones, y lamentablemente las que trae por default no tienen sentido en producción. En esta charla se explora un pequeño conjunto de configuraciones que afectan en mayor o menor medida la calidad de una aplicación en producción. En esta charla (fuertemente inspirada en la dada por Peter Sperl en la Europython 2019) voy a presentar una configuracion que propongo como la inicial para llevar una aplicación a producción detras de un μwsgi. Voy a analizar una a una estas configuraciones, plantear por que el default está mal, como se llegó a ese punto y cual debería ser el valor por defecto.
Disertantes: Mariano "Nassty" García Berrotarán
Te puede interesar...
Remeras

Es una remera calidad PREMIUM (algodón peinado premium, doble refuerzos en hombros, tapa costuras), en color azul marino. El costo de la remera es $620. Y hay un montón de talles para elegir!
Becas
Si te interesa podés leer mas información acá
Descuento en pasajes
Elegí Pycon Ar 2019 Conferencia Nacional del Lenguaje de Programación Python, y el código es PRF75

Código de conducta
PyConAr es un evento de la comunidad que busca mejorar la comunicación y colaboración entre los desarrolladores.
Valoramos la participación de cada miembro de la comunidad de Python y queremos que todos los asistentes tengan una experiencia agradable y satisfactoria. Para ello, se espera de todos los asistentes que se sean respetuosos y educados con el resto de la los asistentes, sea durante la conferencia misma o cualquier otra etapa relacionada.
Para que quede claro lo que se espera, todo delegado, disertante, expositor o voluntario deberá seguir el siguiente Código de Conducta. Los organizadores cuidarán la observación de estas normas durante el evento.
La versión corta
Uno de los objetivos de PyConAr es proveer una experiencia libre de acoso o discriminación para todos, sin distinciones de género, orientación sexual, invalidez, aspecto físico, tamaño corporal, etnia, o religión. No se tolerará la discriminación de los asistentes en ninguna forma.
Todo contenido debería ser el apropiado para una audiencia profesional incluyendo a personas de distintas áreas. Las temáticas y contenidos sexuales no son apropiadas para ninguna instancia del evento.
Se amable con los demás. No insultes o desprecies a otros aisistentes. Compórtate como un profesional. Recuerda que chistes discriminatorios, sexistas, racistas, de acoso no son apropiados para PyConAr.
A los asistentes que violen estas normas se les podrá pedir que abandonen la conferencia sin derecho a reembolso, siendo suficiente para ello el criterio de los organizadores.
Gracias por hacer de este un evento abierto a la comunidad y amistoso.
La versión larga
Acoso incluye comentarios ofensivos relativos a género, orientación sexual, invalidez, aspecto físico, tamaño corporal, etnia, religión, pornografía en espacios públicos, intimidación deliberada, acecho, persecución, acoso por fotografías o grabaciones, constante interrupción de charlas u otros eventos, contacto físico impropio y el acoso sexual.
Los participantes que sean apercibidos por acoso deberán abstenerse inmediatamente.
Se cuidadoso al seleccionar las palabras. Recuerda que los chistes sexistas, racistas y de otras clases pueden ser ofensivos para los demás. El exceso de malas palabras o chistes ofensivos no son apropiados para PyConAr.
Si un participante se comportara de forma que violase el Código de Conducta, los organizadores de la conferencia podrían tomar las medidas que ellos consideren adecuadas, incluyendo el apercibimiento o expulsión de la conferencia, sin derecho a reembolso.
Contacto
Si eres objeto de acoso, notas que alguien más está siendo acosado, o
tienes cualquier otro reclamo, por favor contáctate con uno de los
organizadores del evento o via mail a:
coc@ac.python.org.ar
yamila@ac.python.org.ar
adelfino@gmail.com
Requerimientos para los talleres
Levantar una aplicación Django productiva de cero
Miércoles 13hs a 16hs Sala Invgate(D)Vas a necesitar:
- Homebrew Mac / Linux
- GIT
- Docker Mac / Linux
- Docker Compose (ya incluido en Docker para Mac) / Linux
- Pipenv
brew install pipenv - Curl
brew install curl - NVM
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.1/install.sh | bash" - Node.js
nvm install node - Bitbucket free account
- Heroku free account
Resolviendo la tarea con Jupyter
Miércoles 16.30 a 19.30hs Sala Invgate(D)Vas a necesitar:
Introducción a TDD: Uso, luego implemento
Miércoles 13hs a 16hs Sala J.P.Morgan(C)Vas a necesitar:
- Navegador web de preferencia
- IDE de desarrollo, puede ser PyCharm o Visual Studio Code (les resultará complejo hacerlo usando Jupyter). En el caso de optar por VSCode sugiero el plugin littlefoxteam.vscode-python-test-adapter
- GIT
- Cuenta de Github
Creación y deployment de aplicaciones web para visualización de datos georreferenciados
Miércoles 16.30 a 19.30hs Sala J.P.Morgan(C)Vas a necesitar:
- Python 3.6 o superior
- Navegador web
- Conda
- Geopandas
conda install -c conda-forge geopandas - Plotly
conda install -c ploty ploty - Dash
conda install -c conda-forge dash - (Solo para deployment) Cuenta en Heroku e instalación de Heroku CLI
- Editor de código, ejemplo: PyCharm o Visual Studio Code
- El código fuente que va a ser utilizado durante el taller va a estar disponible en: https://github.com/ramirojc/PyConAr_GeoViz
Workshop LEGO Education®: Creatividad, Innovación y Robótica Educativa
Miércoles 16.30 a 18.30hs Sótano BeatVas a necesitar:
- Editor de código Visual Studio Code
- vscode plugin LEGO Education EV3 instalada y activada lego-education.ev3-micropython
Con el apoyo de:

¿Cómo llegar?
Para poder viajar colectivo, subte, y tren, dentro de la CABA y Gran Buenos Aires, es necesario la tarjeta SUBE Aunque no es necesaria para el subte y tren ya que el mismo se puede comprar el boleto en las estaciones, las ventanillas no están siempre abiertas, asique es recomendable tener la tarjeta sube.
Para manejarse dentro de CABA, sino sabe como llegar de un lugar a otro con el transporte público, hay varias aplicaciones para los celulares:
- BA Cómo Llego: se puede usar para ver que opciones de transporte público uno puede usar para moverse dentro de CABA. Es gratuito, y tiene su versión para Android, y iOS
- BA Subte: indica el estado del subte y tiempos de cuando pasa el próximo para todas las líneas. Es gratuito y tiene su versión para Android y iOS
- Trenes en Directo: indica el estado de las diferentes líneas de trenes, y tiempos de cuando sale el próximo. Es gratuito y tiene su versión para Android y iOS
Subte: tiene un costo de $19,00, y las siguientes líneas le dejan cerca del mismo:
- Línea A: la estación Sáenz Peña le deja a 5 cuadras
- Línea B: la estación Uruguay le deja a 3 cuadras
- Línea C: la estación Diagonal Norte le deja a 6 cuadras
- Línea D: la estación Tribunales le deja a 5 cuadras
Tren: se puede usar la línea San Martín, o la línea Mitrea para ir a Retiro, y desde ahi hay diferentes colectivos que le dejan cerca del Centro Cultural San Martín: 5, 6, 26, 70, 50, 100, 115, o 132. Tambien se se puede tomar la línea Roca para ir a Constitución, y de ahí usar los colectivos: 39, 60, 100, o 102.
Eco bicis: transporte público de bicicletas donde uno puede retirar uno en puntos predeterminados, y lo tiene que dejar en otro punto predeterminado. El servicio es gratuito pero para para poder usarlo es necesario registrarse usando la aplicación de Android o la de iOS. Hay dos puntos de EcoBici a menos de 4 cuadras del Centro Cultural.
Colectivos: tiene un costo mínimo de $18,00, y no se puede usar este servicio al menos que se cuente con una tarjeta SUBE. El mismo funciona las 24 horas (dentro de CABA), aunque a la noche suele tener menor frecuencia. Algunas líneas que tienen paradas cerca del Centro Cultural son 5, 6, 7, 23, 24, 26, 29, 39, 50, 60, 102, 146, 180. Por último, la parada Obelisco Sur del Metrobus 9 de Julio, le deja a unas 5 cuadras.
Taxi: tiene un costo de $45,80 al momento de iniciar el viaje y $ 4,58 por cada 200 metros de recorrido. Entre las 22:00 y las 06:00 rige una tarifa nocturna con un incremento del 20% en el valor del viaje.
Uber: el servicio de Uber funciona en CABA. No tengo informacion del costo del servicio
Otras actividades
Además, del PyCon Argentina 2019, en Capital Federal se pueden hacer otras actividades. Pueden ver un listado más completo y actualizado acá
Qué ver
- MACBA (Museo de Arte Contemporáneo de Buenos Aires): De lunes a viernes de 11 a 19hs (Martes cerrado). Sábado y domingo de 11 a 19hs. Entrada Arancelada. Más información acá
- Planetario: Martes a viernes de 13 a 17hs. Sábados, domingos y feriados 14:30, 15:30, 16:30, 17:30, 18:30, 19:30. La entrada cuesta $120. Más información acá
- Teatro Colón: Todos los días de 9 a 17hs cada 15 minutos. Más información acá
- Catedral Metropolitana: Calle Rivadavia s/n, C1004 CABA
- Palacio San Martín (Ex Palacio Anchorena): Martes y jueves a las 14hs. Viernes 14hs y 17hs. Más información acá
- Legislatura Porteña: de lunes a viernes de 9 a 20hs. Al museo, lunes y viernes de 13 a 17hs.
- Manzana de las Luces: Lunes a domingo de 10 a 21hs. Más información acá
- Centro Cultural Néstor Kirchner: Sábados, domingos y feriados a las 14 y 15:30. Se necesita pasaporte o DNI. Más información acá
- Buque Museo Corbeta Uruguay: todos los días de 10 a 19. La entrada es gratuita. Más información acá
- Buque Museo Fragata Presidente Sarmiento: todos los días de 10 a 19. Entrada libre y gratuita. Más información acá
- MARQ (Museo de Arquitectura y Diseño de la Sociedad Central de Arquitectos): martes a domingo de 13 a 20hs. Entrada arancelada.
- MIFB (Museo de Arte Hispanoamericano Isaac Fernández Blanco): Martes a viernes de 13 a 19hs (lunes cerrado). Sábado, domingo y feriados de 11 a 19hs. Entrada arancelada, pero los miércoles es gratis. Más información acá
- Museo Casa Rosada: de miércoles a domingo de 10 a 18hs. Entrada gratuita. Más información acá
- Museo Histórico Nacional del Cabildo y de la Revolución de Mayo: Martes, miércoles y viernes de 10:30 a 17hs. Jueves de 10:30 a 20hs. Sábado, domingo y feriados de 10:30 a 18hs. Más información acá
- Jardín Japonés: de lunes a domingo de 10 a 18hs. Entrada arancelada. Más información acá
- Reserva Ecológica: Sábados, domingos y feriados de 9:30 a 16hs. Más información acá
Tours
- Visita Guiada a Pie - Plaza de Mayo: domingos a las 15 y 17hs. Require inscripción previa. Más información acá
- Visita Guiada a Pie - San Telmo: domingos a las 15hs. Requiere inscripción previa. Más información acá
- Visitas guiadas a pie - La Boca. viernes a las 15hs. Requiere inscripción previa. Más información acá
- Visitas guiadas a pie - Recoleta: miércoles a las 15hs. Requiere inscripción previa. Más información acá
- Visitas guiadas a pie - Bosques de Palermo: jueves a las 17hs. Requiere inscripción previa. Más información acá
- Visitas guiadas a pie - Puerto Madero: lunes a las 17hs. Requiere inscripción previa. Más información acá
- Visitas guiada a pie - Retiro: todos los martes a las 17hs. Requiere inscripción previa, y tiene una duración de 90 minutos. Más información acá
- Visitas guiadas nocturnas - Puerto Madero: cuarto viernes del mes a las 20hs. Requiere inscripción previa. Más información acá
- Visita guiada nocturna - Calle Arroyo: primer viernes de cada mes a las 20hs. Requiere inscripción previa, y tiene una duración de 90 minutos. Más información acá
- Trekking Urbano - 5km - Circuito Sur: Lunes y viernes a las 10hs. Requiere inscripción previa, y tiene una duración de 4 horas. Más información acá
- Trekking Urbano - Desafío 18km: todos los domingos a las 10hs. Requiere inscripción previa, y tiene una duración de 6 horas. Más información acá
- Circuito Papal: sábados y feriados a las 15hs. Domingos a las 9 y 15hs. Requiere inscripción previa. Más información acá
- BA Remo: miércoles y domingos a las 10:45 y 12:15. Requiere inscripción previa, y tiene una duración de 90 minutos.
- Bici Tour BA - Los 6 sentidos de La Boca: lunes a viernes a las 11 y 15hs. Requiere inscripción previa, y tiene una duración de 75 minutos. Más información acá
- Bici Tour BA - Los 6 sentidos de Palermo: sábados, domingos y feriados a las 11hs. Requiere inscripción previa, y tiene una duración de 75 minutos. Más información acá
- Bici Tour BA - Los 6 sentidos de Recoleta: lunes a viernes a las 11hs y 15hs. Requiere inscripción previa, y tiene una duración de 75 minutos. Más información acá
- Arte urbano - Palermo: tercer sábado de cada mes a las 11hs, y segundo martes a las 15hs. Requiere inscripción previa, y tiene una duración de 90 minutos. Más información acá
- Arte urbano - Barracas: cuarto sábado de cada mes a las 11hs, y primer martes a las 15hs. Requiere inscripción previa, y tiene una duración de 90 minutos. Más información acá
Otros eventos de interés
- Visitas guiadas al Palacio Barolo: del 27 de agosto al 10 de diciembre. Lunes, miércoles, y jueves a las 10, 12, 14, 16, 17, 18 y 19hs. Viernes: 10, 12, 13, 14, 15, 16, 17 y 18hs. Sábados: 10, 11, 12, 13, 14, 15, 16, y 18hs. No se recomienda la visita a personas con movilidad reducida. Más información acá
- Gala Lírica Progetto Fabbrica - Teatro Dell'Opera Di Roma: El Programa de Artistas Jóvenes «Fabbrica», fundado y dirigido por Eleonora Pacetti, nace en 2016 por voluntad del nuevo Director General de la Opera di Roma, Carlo Fuortes. Más información acá
- La Medicina. Tomo I: Los órganos agotan sus fechas de vencimientos y las medicinas acuden para que la falla desfallezca, con la ilusión que el cuerpo se divide como las chacras. Más información acá
- Dios salve a la reina: El homenaje de God Save the Queen a Queen el 6 de diciembre con un nuevo y tremendo espectáculo en Luna Park, lo mejor de sus 20 años de carrera. Más información acá
- BARBE RIA en la barbería: En una BARBERÍA que también es BAR, tres comediantes hacen que todo el mundo RÍA. Como si fuera poco, la Barbería La Época es el único Museo Viviente del mundo declarado por la National Geographic. Más información acá
- Italia XXI - Ciclo De Música, Danza, Ópera y Teatro: Creado por el Teatro Coliseo, en colaboración con el Ministerio de Bienes Culturales de Italia y el Istituto Italiano di Cultura de Buenos Aires, y con el auspicio de la Embajada de Italia en Argentina, el ciclo Italia XXI es un proyecto de revitalización y relanzamiento de la oferta cultural italiana en Buenos Aires y en Argentina. Más información acá
- Damas gratis: Damas Gratis conquista el Luna Park el 8 y 9 de diciembre. Más información acá
- Entre actos: El reconocido artista y diseñador argentino Pablo Reinoso presenta los actos de Entre (s), un trabajo diseñado especialmente para CCK. Más información acá
¿Donde almorzar?
Dentro de las salas del Centro Cultural no se puede llevar bebidas ni comida, pero si se puede tomar y beber en el hall. Una lista de lugares a donde salir a almorzar los días del evento:
- Burger King: Av. Corrientes 1770. 3 cuadras. Hamburguesas.
- Mc Donalds: Av Callao 131. 4,5 cuadras. Hamburguesas.
- Mc Donalds: Av. Corrientes 992/6. 6 cuadras. Hamburguesas.
- Dellepiane Bar: Luis Dellepiane 685. 6 cuadras. Hamburguesas.
- El Palacio de la Papa Frita: Av. Corrientes 1612. Hamburguesas.
- Sattva: Montevideo 446. 2 cuadras. Restaurante. Cuenta con opciones vegetarianas
- Tataki Restaurante: Rodríguez Peña 433. 3 cuadras. Restaurante de comida peruana
- Green life: Av. Corrientes 1915. 5 cuadras. Restaurante. Cuenta con opciones vegetariana
- Parrilla Peña: Rodríguez Peña 682. 5 cuadras. Restaurante
- Kentucky: Av. Corrientes 1502. 2 cuadras. Pizzeria
- La Continental: Av. Callao 361. 3 cuadras. Pizzeria
- La Continental: Av. Callao 202. 3 cuadras. Pizzeria
- Pizzería Güerrin: Av. Corrientes 1368. 3 cuadras. Pizzeria
- Los Inmortales: Av. Corrientes 1369. 3 cuadras. Pizzeria
- La Americana: Av. Corrientes 1383. 3 cuadras. Pizzeria
- Banchero: Av. Corrientes 1300. 4 cuadras. Pizzeria
- Starbucks: Cerrito 336. 5 cuadras. Cafe
- La Paz: Av. Corrientes 1593. 2 cuadras. Cafe
- Café Martínez: Uruguay 463. 3 cuadras. Cafe
- Cafetería Uruguay: Uruguay 485. 3 cuadras. Cafe
- La Birreria: Sarmiento 1635. 1 cuadra. Bar
- Covo Birreria: Montevideo 382. 2 cuadras. Bar
- Dellepiane Bar: Luis Dellepiane 685. 5 cuadras. Bar