Duodécima Conferencia Argentina de Python
PyConAr
16 al 27 de Noviembre de 2020
Primer Edición Virtual
Este año se realizará la primer edición virtual de la PyCon Argentina y esto resulta en un gran desafío tanto para la organización como para speakers y sponsors.
Decidimos optar por un cronograma más espaciado en el tiempo, para evitar jornadas intensivas en las que la audiencia tenga que pasar mucho tiempo enfrente de una pantalla. Como ya mencionamos, la PyCon durará dos semanas y cada día habrá cuatro charlas de media hora (dos horas de charlas en total).
Como entendemos que en este tipo de eventos la comunicación es crucial, elegimos dos herramientas para utilizar durante la conferencia que apuntan a tener canales de comunicación claros, fluidos y fáciles de usar.
Discord
Discord es una aplicación de chat que también permite hacer videollamadas y streaming de video. Vamos a tener un servidor exclusivo para la PyCon en el cual habrá distintas salas de chat (en Discord se llaman “canales”), cada una con un propósito específico.
Habrá un canal para cada charla en donde se podrán seguir las discusiones relacionadas a tópicos específicos, otro canal hará las veces de hall en donde todos los participantes podrán interactuar entre sí de manera informal, por mencionar algunos.
Esta herramienta está disponible para todas las plataformas.
YouTube Live
Las charlas oficiales de la conferencia serán transmitidas por YouTube Live, por ser el medio más utilizado para transmisión en vivo, disponible también en todas las plataformas y que permite dejar grabadas las charlas dadas durante la conferencia.
Si querés saber más consulta nuestras FAQs sobre el evento
Acerca del evento
La PyCon (Python Conference) es una convención anual para la discusión y promoción del lenguaje de programación Python. Se originó en Estados Unidos pero hoy en día se realiza en ese país, en Europa, España, Brasil, Inglaterra, Italia, China, y en otros treinta países.
Desde 2009 se realiza también en Argentina, ese año en CABA, siendo declarado de Interés Cultural por la Ciudad de Buenos Aires. En consecuencia al carácter federal de nuestro país, las siguientes ediciones se realizaron en diferentes ciudades: Córdoba, Junín, Rosario, Quilmes, Rafaela, Mendoza y Bahía Blanca.
La PyCon Argentina reúne a gran parte de la comunidad de habla hispana, de todas las edades y con un fuerte acento en diversidad. Es gratuita y abierta a todo público, dirigida a profesionales, estudiantes, académiques, empresaries, trabajadores, funcionaries públiques, entusiastes; es decir, se trata de un evento inclusivo y para todes. El número de asistentes crece año a año, rondando las 1080 personas en el último año, en CABA.
En general el evento es de tres días: miércoles, jueves y viernes; el primer día de talleres y tutoriales y los siguientes dos días para charlas ya en formato conferencia clásica así como también espacios abiertos, talleres, y diferentes ámbitos pensados para la interacción de la comunidad de Python con otras comunidades, empresas e instituciones gubernamentales.
El material presentado incluye todos los niveles, desde lo más orientado a principantes como los talleres y tutoriales del primer día, hasta charlas de nivel avanzado con calidad internacional, dadas por invitades de otros países o por disertantes locales que también dan charlas similares en conferencias de otros países.
El evento está organizado por la comunidad de Python Argentina, cuyo objetivo es nuclear a les usuaries de Python y promover su uso. Python es un lenguaje de programación, de licencia abierta y libre, que es cada día más popular en la enseñanza, la industria y la ciencia, y es el lenguaje de mayor crecimiento en los últimos años. La comunidad cuenta con el soporte formal de la Asociación Civil Python Argentina.
Charlas

Airflow en Kubernetes: Escalando al mas alla!
Vamos a aprender a hacer pipelines en Airflow, como testearlos para que estemos confiades de nuestros cambios y vamos a deployarlos en Kubernetes para poder escalar Airflow tanto como se necesite. Mate incluide.
Disertantes: Axel Sirota

Análisis de datos con Pandas
Un taller mostrando el analisis de datos usando Jupyter Notebook, Panda, MatploLib. Como depurar datos y generar gráficos.
Disertantes: Sofía Martin

AppSec Vulnerability Management Pipelines
Abordaremos un enfoque práctico para la gestión de vulnerabilidades en entornos de entrega e integración continua, a través de AppSec pipelines, tools para staging de hallazgos y escalamiento
Disertantes: Agustin Celano

Automatizando releases con commitizen y github actions
Automatizaremos una release de un paquete open source en python, veremos como este proceso puede simplificar la vida de un maintainer.
Disertantes: Santiago E Fraire W

"Behave" para entender al usuario
Únete a esta charla si quieres aprender sobre Behavior Driven Development, una técnica que permite entender de forma clara el comportamiento que esperan ver los usuarios en el software, escribiendo casos de prueba en lenguaje natural que no programadores puedan leer y entender. Aprenderás por qué esta técnica hace ágiles los proyectos y mantiene en armonía a los equipos de desarrollo y los stakeholders del negocio, además de cómo implementar BDD en Python con ayuda de Behave.
Disertantes: María Camila Guerrero Giraldo
Buenas prácticas para enseñar programación online
"Buenas prácticas para enseñar programación online" es una charla destinada a introducir buenas prácticas basadas en evidencia para el diseño de materiales, la gestión del aula y la accesibilidad.
Disertantes: Patricia Loto, Nicolás Palopoli, Mariela Rajngewerc,
Charlas Relámpago
Las charlas relámpago son disertaciones cortas de 5 minutos en las que una persona explica una idea o un tema rápidamente.
Disertantes: La Comunidad

Coding as a Service: librería pypsdier, aprendizajes y metodología
¿Cuál es la mejor manera para compartir un código, de manera que sea fácil de instalar, reproducible y fácilmente actualizable? En el desarrollo de la librería pypsdier (simulación numérica de ecuaciones de reacción difusión para catalizadores en medio poroso) hemos enfrentado estos desafíos y desarrollado una metodología que nos ha permitido iterar rápidamente y entregar “Coding as a Service” con facilidades tanto para el desarrollador como el usuario final.
Disertantes: Sebastian Flores Benner

Como desarrollar un switch de capa 2 sobre un controlador SDN con Ryu framework
Las redes definidas por software (SDN) vienen a cambiar la forma en la que pensamos como las aplicaciones se vinculan con las redes sobre las que funcionan. En esta charla intentaré dar una breve introducción a la arquitectura y protocolos propuestos por SDN y como desarrollar nuevas funcionalidades de red usando un framework/controlador hecho en Python.
Disertantes: Joaquin Gonzalez
Conozco un grupo de objetos que resuelven problemas
Los Decoradores: Ep.1 El origen de una solución Ep.2 El problema en la serpiente Ep.3 Cuatro porciones para llevar Ep.4 El recambio de yerba
Disertantes: Augusto `Sasha` Kielbowicz

C para Pythonistas
Se explicarán los conceptos más característicos del lenguaje C comparándolo con conceptos iguales o similares presentes en el lenguaje Python, con el objetivo de facilitar su aprendizaje.
Disertantes: Agustín Scaramuzza

Dataclasses to rule 'em all
Breve introducción al uso de Dataclasses de Python 3.7. Qué son, para qué sirve y por qué está bueno usarlas.
Disertantes: Leandro E. Colombo Viña (Aka @Lecovi)
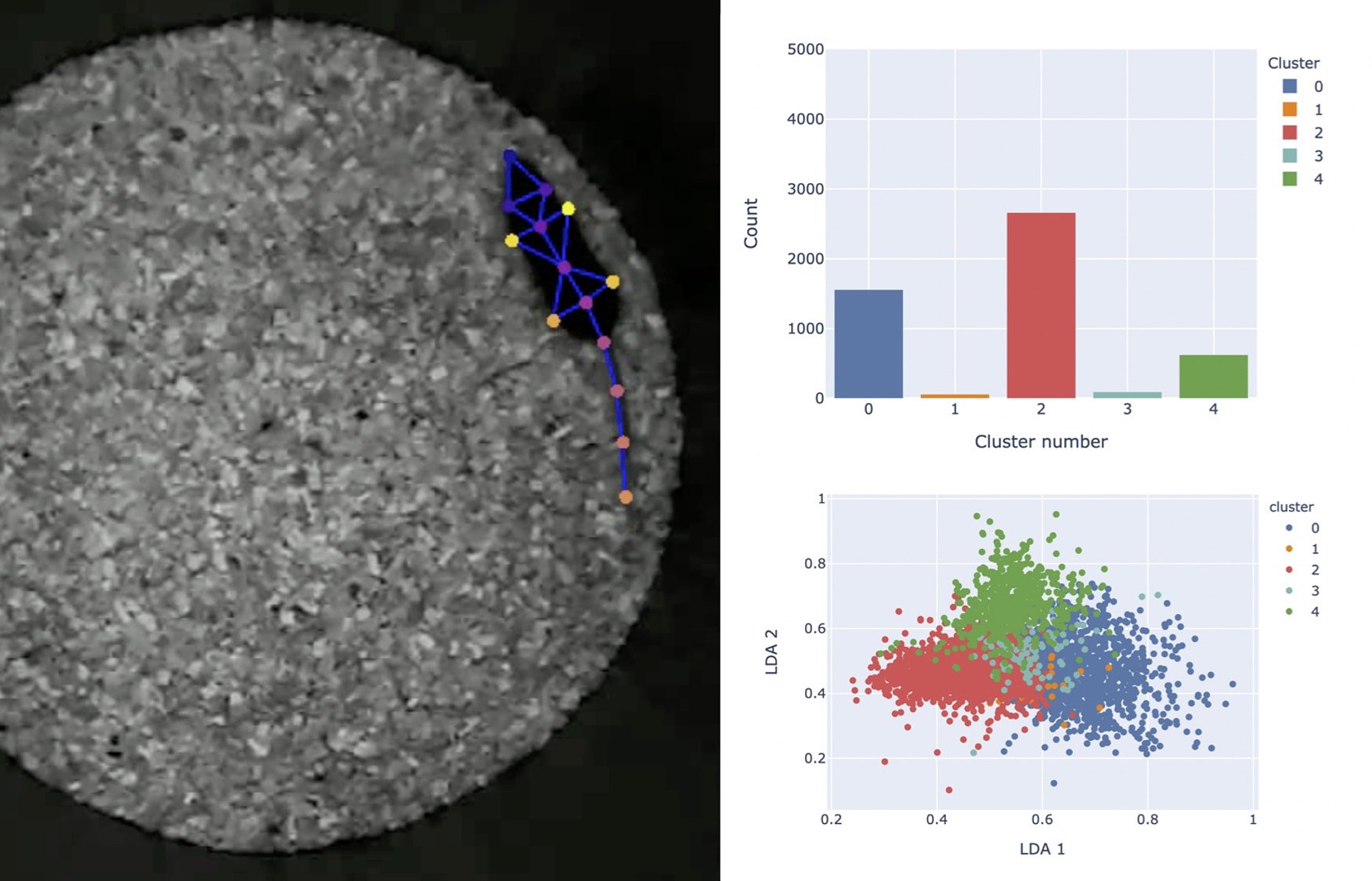
DeepOF: un paquete para el análisis de series temporales de animales en libre movimiento
El análisis de videos de animales comportándose libremente (así como la comparación de videos correspondientes a distintas condiciones) es crucial para la investigación en psiquiatría, ya que permite estudiar las consecuencias en el comportamiento de distintos estímulos. Este tipo de estudios se ha visto facilitado durante los últimos años gracias a avances en computer vision y deep learning. Esta charla introduce deepof, una suite de herramientas para postprocessing de series temporales extraídas de video implementada en python y tensorflow 2.0. La disertación se enfoca tanto en los algoritmos como en la importancia de las DevOps en ciencia.
Disertantes: Lucas Miranda

Desarrollo web con Python: introducción a Django
Django es la herramienta más usada hoy en día para hacer desarrollo web en Python, en gran medida gracias a lo poderoso que es, pero también a lo sencillo que es comenzar a utilizarlo, como veremos en esta charla.
Disertantes: Juan Pedro Fisanotti

Diseño de RESTful Web APIs
En esta charla presentaremos a REST como uno de los estilos de arquitectura de APIs dominantes en la actualidad. Vamos a introducir los conceptos y componentes básicos pero fundamentales presentes en el estilo de arquitectura, entendiendo cómo se relacionan y qué restricciones se deben aplicar a los mismos para que se ajusten a los estándares RESTful.
Disertantes: Mariano Martinelli

Elasticsearch no reemplaza a Mysql/Psql, pero cómo ayuda!
Un breve recorrido sobre la integración de ES en nuestro código para optimizar tu search, find o get.
Disertantes: Ignacio Nicolás Feijoo

Engineer
Mostraré cómo utilizo Python para descargar datos públicos para posteriormente realizar análisis explorativo y/o auditoria de datos.
Disertantes: Karl Niebuhr

Filesystems a los bytes, con python
O cómo leer un filesystem solamente con python y su librería estándar
Disertantes: Bruno Constanzo

Great Expectations: Validar data pipelines como un profesional
Cuando hablamos de validaciones lo primero que pensamos es en el código, unit test, integration tests, etc. Pero ¿Quién mira a los datos? Great Expectations!
Disertantes: Eric Rishmüller

Houdini un poroto... Python Magic Methods!
Fácilmente identificables por sus “dunders” o “double underscores”, los Magic Methods son métodos especiales que permiten definir el comportamiento de un objeto ante los operadores provistos por Python y ante determinadas circunstancias. En esta charla veremos cómo se utilizan, cuáles son sus ventajas y qué aplicaciones prácticas pueden tener.
Disertantes: Rodrigo Cetera, Lucas Esposito

Internet of Things con Raspberry PI y Python
Conectemos todo a Internet. La idea de esta charla es introducirnos al mundo IOT y sobre cómo podríamos iniciar un proyecto con nuestro Raspberry Pi y Python. Adicionalmente, veremos ejemplos caseros de Domótica y Seguridad.
Disertantes: Sebastian Bauer

Introducción al Análisis de Supervivencia con Python
Predecir cuándo va a ocurrir un evento determinado se ha vuelto un requerimiento muy común en la industria, donde surgen preguntas del estilo: “¿cuánto tiempo funcionará un equipo hasta que presente una falla?”, “¿En cuanto tiempo un usuario dará de baja su suscripción (churn)?”, “¿Cuánto sobrevivirá un paciente luego de ser diagnosticado con una enfermedad?”. Estas interrogantes pueden ser abordadas con Análisis de Supervivencia. En esta charla estaremos explicando los conceptos relacionados a esta técnica y cómo generar respuestas con Python.
Disertantes: Bruno Marengo, Jesús Golindano, César Morichetti

Introducción al procesamiento de imágenes con Python
un agente racional que aprende, no omnisciente, que al entrenarlo aprenda a partir de sus percepciones y le permita ser autónomo gracias a la experiencia adquirida. Se mostrará las 6 etapas básicas de procesamiento de imágenes para ese agente y su correspondiente implementación en Python.
Disertantes: Carlos Bustillo

Introducción a type hints
Comenzando con Python 3 y con cada nueva versión desde entonces, el lenguaje ha incorporado diversas herramientas para expresar el tipado de nuestro código mediante type hints. Si bien estos chequeos no se aplican en tiempo de ejecución, aplicaciones que pueden incorporarse en nuestro proceso de integración continua pueden interpretarlos y advertirnos de diferentes problemas.
Disertantes: Andre Delfino

Jupyter Notebook en la enseñanza de física ambiental
Desarrollo de gráficos animados, con uso de gifs y widgets acompañados con texto científico para explicar la estabilidad atmosferica a estudiantes universitarios en un contexto de carencias de conectividad y equipos, en Salta.
Disertantes: Ignacio Joaquin Arroyo, Veronica Mercedes Javi, Sebastian Ismael Arroyo

Keynote - Simon Willison
Simon is the creator of Datasette, an open-source tool for exploring and publishing data.
Disertantes: Simon Willison

Keynote - Transistemas
Todas las personas deben gozar de los mismos derechos. El proyecto nació principalmente de la necesidad de resolver la falta de insersión laboral de las personas trans en empleos formales. La educación es una de las claves, por eso pensamos que educarse es necesario y decidimos organizar cursos gratuitos para ello, pero era solo el comienzo.
Disertantes: Transistemas

La API de tu currículum vitae
Vamos a crear una API con Python y Flask, mediante la cual podrás mostrar tu currículum vitae al mundo. Después vamos a subir el código a Github, y luego relacionar nuestra cuenta con Heroku, para hacer el deploy y que nuestra API esté publicada al mundo. Al finalizar, tendrás un proyecto funcionando y una API que le podrás pasar a tus contactos de RRHH!
Disertantes: Nahuel Tori

Machine learning Libre: modelando conversaciones con Rasa y Python
Qué involucra una conversación humana? Qué desafíos se escanden detrás de la naturalidad del lenguaje natural? Podemos modelar esto más allá de reglas, ifs y elifs? Sí, podemos modelar este problema, y así ayudar a personas a través de asistentes virtuales conversacionales. Esta charla busca introducir las preguntas existenciales detrás de los asistentes virtuales que usan machine learning, para proponer algunas respuestas y construir intuiciones. Se introducirá a Rasa, un framework de Python para esto, que es Software Libre.
Disertantes: Karen Palacio, Florencia Alonso, Brandon Janes. (Kunan Sa)

Mejorando el acceso a la mecanización de pequeños productores arigcolas con Python y GeoDajngo
Python tiene un ecosistema muy interesante para el desarrollo de aplicaciones que hacen uso de GIS. También es una excelente herramienta para el análisis de datos y consumo de datos IoT. Esta charla intenta introducir la experiencia de trabajar con proyecto de Python consiente en un back-end para aplicaciones móviles y aplicación web y un conjunto de herramientas para facilitar el trabajo de analistas de datos.
Disertantes: Nahuel Defosse

Pasaron cosas: logging efectivo para entender qué sucedió
El logging es una técnica indispensable en el software productivo, pero hay muchos conceptos y una API confusa que hacen su uso innecesariamente complicado. Entendamoslo... antes del segundo semestre.
Disertantes: Martín Gaitán

Peewee
Peewee es un ORM simple y pequeño. Tiene pocos conceptos (pero expresivos), lo que lo hace fácil de aprender e intuitivo de usar.
Disertantes: Jose Oscar Vogel
¿Por que no se hacen mas tests?
Hablar un poco sobre test en gral y lo que uno se encuentra al iniciar en esta practica. Mostrar algún ejemplo práctico, para pasar por los conceptos principales. Todo orientado a pytest.
Disertantes: Mariano Bianchi, Andrés Ramírez

Pythonic APIs con GraphQL
GraphQL es un nuevo paradigma a la hora de diseñar nuestras APIs. Vamos a hablar sobre cómo podemos programar una API Pythonica mediante GraphQL que todos nuestros clientes amen consumir
Disertantes: Nahuel Ambrosini

Python para DevSecOps
La eficiencia de las implementaciones DevSecOps se ve favorecida por la incorporación de Python a las habilidades de Equipos de Seguridad Ágiles
Disertantes: Alfredo Pardo

Python worst Practices AKA Anti-Patterns
This talk is aim to summarize the common Anti-Patterns in Python. It is overwhelming to see so many resources to learn best practices in Python. However it is more scary that there are very few places which will teach you what you should NOT do while coding.
Disertantes: Pratibha Jagnere

Python y C un solo corazón
SAn compartirá su experiencia desarrollando el software de comunicaciones de un satélite usando Python y CFFI.
Disertantes: Santiago Piccinini

Recetas para ser más feliz con Docker.
Docker es una de las herramientas de mayor crecimiento en los últimos años. Esto se debe a la simplicidad con las que nos permite armar grandes entornos tanto locales como en producción. En esta charla nos centraremos en repasar algunos conceptos básicos para poder crear un entorno de desarrollo simple y confiable, que se parezca lo más posible a nuestro entorno productivo y así evitar sorpresas a la hora de hacer un deploy.
Disertantes: Serafin Fernandez

Rompiendo el monolito
Experiencias de descomposición y/o extracción de funcionalidad en microservicios, como forma de hacer frente a la deuda técnica y la mantenibilidad del código
Disertantes: Guillermo Narvaja, Gabriel Parrondo
Speed Interviews - Sesión 1
Las speed interviews son entrevistas de 10 minutos con cada uno de los 7 sponsors que participan de la actividad este año.
Disertantes: Sponsors E Inscriptos
Speed Interviews - Sesión 2
Las speed interviews son entrevistas de 10 minutos con cada uno de los 7 sponsors que participan de la actividad este año.
Disertantes: Sponsors E Inscriptos
Speed Interviews - Sesión 3
Las speed interviews son entrevistas de 10 minutos con cada uno de los 7 sponsors que participan de la actividad este año.
Disertantes: Sponsors E Inscriptos
Speed Interviews - Sesión 4
Las speed interviews son entrevistas de 10 minutos con cada uno de los 7 sponsors que participan de la actividad este año.
Disertantes: Sponsors E Inscriptos
Speed Interviews - Sesión 5
Las speed interviews son entrevistas de 10 minutos con cada uno de los 7 sponsors que participan de la actividad este año.
Disertantes: Sponsors E Inscriptos
Speed Interviews - Sesión 6
Las speed interviews son entrevistas de 10 minutos con cada uno de los 7 sponsors que participan de la actividad este año.
Disertantes: Sponsors E Inscriptos

SQLite, la (des) conocida super hormiga
SQLite, disponible desde hace tanto tiempo y tan desconocido. Es una base de datos relacional, optimizada para ser pequeñísima, rápida, flexible, para usos individuales, sus grandes bondades, especialmente a la hora de integrarlo a nuestro software en Python y las múltiples posibilidades que da para ser optimizado para los más variados usos, son mayormente desconocidas
Disertantes: María Andrea Vignau
Una Apología Poética: Poetry para manejo de dependencias y empaquetado de módulos.
Poetry es una herramienta para manejo de dependencias y empaquetado de módulos. Mostraremos, a través de un ejemplo, porque consideramos que es una versión superadora a alternativas preexistentes (como virtualenvs, setuptools y pipenv) y como integrarlo con otras herramientas modernas del ecosistema (como pyenv o pipx).
Disertantes: Pedro Ferrari
Únete a traducir la documentación de Python
En esta presentación se dará a conocer al proyecto python-docs-es, se mostrará lo facil que es contribuir en la traducción de la documentación de Python
Disertantes: Emmanuel Arias

Unit Testing: Qué testear y cómo testear con pytest.
¿Y esto cómo lo testeo? En esta charla quiero abordar algunas dudas típicas al momento de escribir tests. Voy a hablar de mocks, de buenas prácticas, voy a dar algunos tips y voy a mostrar ejemplos de todo esto usando pytest en su máximo esplendor.
Disertantes: Sofía Denner

Visual Search, de 0 a POC!
Te contamos cómo en unos simples pasos, usando herramientas open source, llevamos a cabo una POC para Mercado Libre. Este experimento se enfoca en mejorar la experiencia de búsqueda de los usuarios. Queremos presentarles Visual Search: un proyecto que todavía está en fase "incubadora" pero que tiene como objetivo encontrar ítems publicados en el portal parecidos a una imagen o foto que el usuario pueda cargar, basándose en la similitud de imágenes.
Disertantes: Facundo Salmeron, Francisco Yackel, Elbio Zapata, Diego Garcia
Keynote


Sponsors

FAQ
¿Como van a ser las charlas virtuales?
Para poder asegurar la calidad de las ediciones pasadas las charlas van a ser grabadas previamente, editadas y transmitidas por YouTube Live durante el evento . A su vez, cada charla tendrá un canal exclusivo en Discord en donde el disertante podrá responder preguntas y continuar discusiones con posterioridad al evento.
A cada charla le corresponde un slot de 30 minutos en total. Siendo que el video de la charla no debe superar los 20 minutos de duración.
¿Qué tengo que tener en cuenta para esta edición virtual?
Por empezar las propuestas a charlas deben cargarse para su evaluación en:
Quiero proponer una charla o taller en PyConAr2020
La fecha límite de envío de propuestas de charlas es el 15 de septiembre inclusive.
La misma debe tener los siguientes datos:
- Título
- Sumario: Un párrafo, como para ser incluido en el programa de charlas
- Descripción de la charla: Uno o dos párrafos que expliquen no tan brevemente el contenido de la presentación, para su evaluación.
- Autore(s): Nombre y apellido, breve descripción, foto, asociación, organismo, o empresa a la que pertenece, si corresponde.
- Tiempo estimado de duración: Las charlas generalmente son de 20 minutos. En caso de que sea mayor o menor el tiempo requerido solicitamos su justificación.
- Nivel objetivo de la charla: introductorio / intermedio / avanzado
- Tipo de público: Avanzado / Intermedio / Principiante / Docentes / Público en general.
- Conocimientos previos: Especificar qué conocimientos previos se deberán tener para seguir sin problemas la charla.
- Tags: web, GUI, databases, frameworks, ORM, IDE, ciencia, educación, juegos, comunidad, etc.
- Teléfono del autor/es (para poder comunicarnos)
- Ciudad de residencia del autor/es.
- OpenDocument (Openoffice.org / LibreOffice)
- HTML standard
- PostScript
- Texto plano
El envío de presentaciones debe tener alguno de los siguientes formatos:
Una vez finalizado el período del envío de propuestas se realizará una selección de las charlas disponibles.
A los disertantes seleccionados, antes de recibir la grabación definitiva, les vamos a pedir un mini video de 1 o 2 minutos para verificar la calidad de grabación
Una vez seleccionadas las charlas y realizada la prueba del mini video van a poder trabajar en la grabación definitiva de la charla.
Ya que cada video lleva un trabajo de edición en donde se incluirán logos o anuncios de sponsors e información sobre el evento, es de suma importancia que se respeten los plazos establecidos para evitar imprevistos en la organización y tener el tiempo suficiente de hacer una edición de la calidad que la PyCon amerita.
También es importante especificar una licencia que permita que la presentación pueda ser descargada del sitio web de PyAr. Se recomienda Creative Commons o similares.
Durante la conferencia, los speakers deberán estar online al momento de transmisión de la charla para poder responder las preguntas generadas.
Planificamos un protocolo que podrán revisar si son seleccionados como speaker de la conferencia y los organizadores estaremos disponibles para cualquier consulta o ayuda que necesiten.
¿Y los talleres?
Los talleres serán transmitidos mediante YouTube Live y la interacción será mediante Discord.
El espacio dedicado a los talleres será los días sábados por la mañana, aunque al disponer de dos semanas para toda la conferencia, este puede adaptarse a las propuestas de quienes dicten el taller. Siempre y cuando estos no se superpongan con los slots de charlas, el resto del espacio de la conferencia estará dedicado a actividades como los talleres o sprints.
¿Puedo proponer alguna actividad que no esté especificada acá?
¿Tenes una idea y querés compartirla? ¿Querés dar un taller o proponer una actividad para la PyCon? ¡Escribinos a charlas@python.org.ar con tu propuesta.
Código de Conducta
PyConAr es un evento de la comunidad que busca mejorar la comunicación y colaboración entre los desarrolladores.
Valoramos la participación de cada miembro de la comunidad de Python y queremos que todos los asistentes tengan una experiencia agradable y satisfactoria. Para ello, se espera de todos los asistentes que se sean respetuosos y educados con el resto de la los asistentes, sea durante la conferencia misma o cualquier otra etapa relacionada.
Para que quede claro lo que se espera, todo delegado, disertante, expositor o voluntario deberá seguir el siguiente Código de Conducta. Los organizadores cuidarán la observación de estas normas durante el evento.
La versión corta
Uno de los objetivos de PyConAr es proveer una experiencia libre de acoso o discriminación para todos, sin distinciones de género, orientación sexual, invalidez, aspecto físico, tamaño corporal, etnia, o religión. No se tolerará la discriminación de los asistentes en ninguna forma.
Todo contenido debería ser el apropiado para una audiencia profesional incluyendo a personas de distintas áreas. Las temáticas y contenidos sexuales no son apropiadas para ninguna instancia del evento.
Se amable con los demás. No insultes o desprecies a otros aisistentes. Compórtate como un profesional. Recuerda que chistes discriminatorios, sexistas, racistas, de acoso no son apropiados para PyConAr.
A los asistentes que violen estas normas se les podrá pedir que abandonen la conferencia sin derecho a reembolso, siendo suficiente para ello el criterio de los organizadores.
Gracias por hacer de este un evento abierto a la comunidad y amistoso.
La versión larga
Acoso incluye comentarios ofensivos relativos a género, orientación sexual, invalidez, aspecto físico, tamaño corporal, etnia, religión, pornografía en espacios públicos, intimidación deliberada, acecho, persecución, acoso por fotografías o grabaciones, constante interrupción de charlas u otros eventos, contacto físico impropio y el acoso sexual.
Los participantes que sean apercibidos por acoso deberán abstenerse inmediatamente.
Se cuidadoso al seleccionar las palabras. Recuerda que los chistes sexistas, racistas y de otras clases pueden ser ofensivos para los demás. El exceso de malas palabras o chistes ofensivos no son apropiados para PyConAr.
Si un participante se comportara de forma que violase el Código de Conducta, los organizadores de la conferencia podrían tomar las medidas que ellos consideren adecuadas, incluyendo el apercibimiento o expulsión de la conferencia, sin derecho a réplica.
Contacto
Si eres objeto de acoso, notas que alguien más está siendo acosado, o
tienes cualquier otro reclamo, por favor contáctate con uno de los
organizadores del evento o via mail a: